
Anyone who knows me for long must have learned I am a crazy fan of chocolate. Whenever I need some pick-me-up, a block of Dark Chocolate with Sea Salt will make my day. On those rainy gloomy day, how can anything beat a cup of hot chocolate with just a hint of cinnamon? But what does chocolate has got to do with MySQL Workbench?
Well, part of my Database unit heavily relies on SQL. I gotta play with MySQL Workbench, which is my favourite toy at the moment to complete the assignment. So on a chilly weeping morning when it feels like a crime to even leave the bed, let’s do something fun, shall we? Together, we will explore a dataset about chocolate and brush up on a few SQL concepts, with some tips and tricks to troubleshoot and resolve hiccups along the way. Let’s dive right in!
1. About our yummy dark chocolatey dataset
This Kaggle dataset contains expert ratings of over 1,700 individual chocolate bars, along with information on their regional origin, percentage of cocoa, the variety of chocolate bean used and where the beans were grown. You may download the dataset from here.
The Flavours of Cacao Rating is based on a 5-point scale.
- 5= Elite (Transcending beyond the ordinary limits)
- 4= Premium (Superior flavor development, character and style)
- 3= Satisfactory (3.0) to praiseworthy (3.75) (well made with special qualities)
- 2= Disappointing (Passable but contains at least one significant flaw)
- 1= Unpleasant (mostly unpalatable)
2. Define the goal
Considering how much I love my dark chocolate, I usually read the labels carefully before purchasing and love to try new brands and origins. Therefore, from this dataset, I would love to learn how to make a better decision when looking for the next moreish dark chocolate bar.
3. Get the data
3.1. Before we begin
We will be using MySQL Workbench for our analysis. So 3 things need to happen to set up the MySQL Workbench before data import.
- Download and install MySQL Workbench
- Create a new MySQL Connection
- Create a new schema named “chocolate”
3.2. Import CSV file
I will be using the MySQL Table Data Import Wizard to import the CSV file (which I have downloaded and saved in a folder).
My first attempt failed with the below error message for “Can’t analyze file”, so let’s do a bit of troubleshooting by selecting OK and click on the wrench symbol to fix the settings.
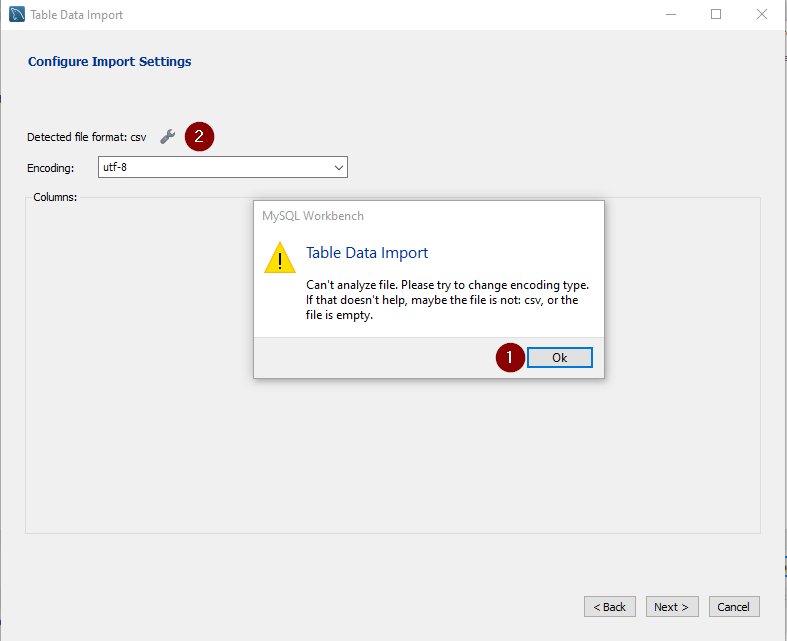
Check for Import Settings
The Import Wizard comes with default settings (see below screenshot). But sometimes we will encounter CSV files with different settings for Encoding, Line Separator and Field Separator. Try forcing a square through a circle never works. So the question will be “How do we check the CSV file’s settings?”
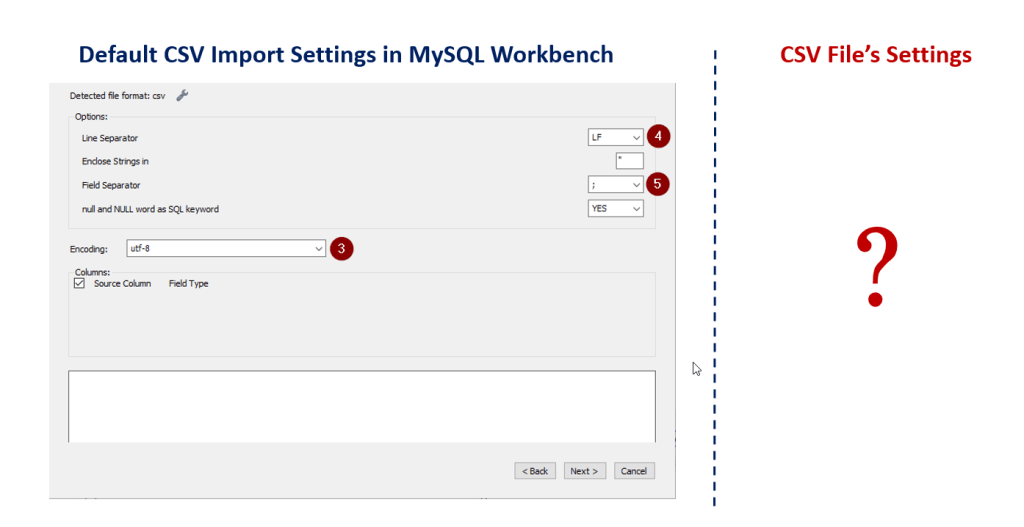
Luckily there is a simple way to check. All we need to do is go to your CSV file, right-click and select “Edit with Notepad ++” and here is what I got.
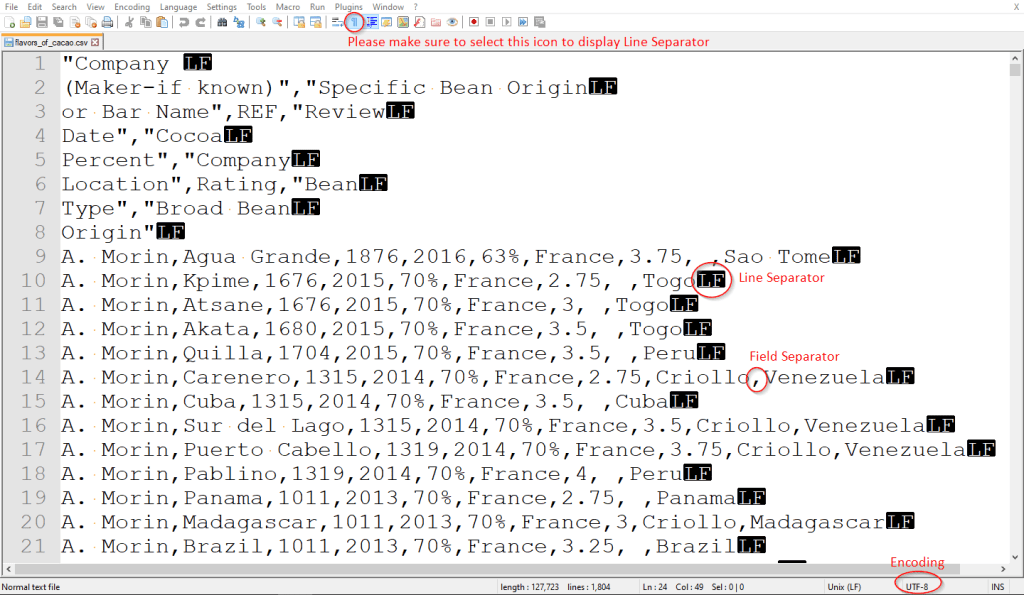
However, guess what, after matching all of the settings with the CSV file, I can’t still make the CSV import work. So what shall we do? Hmm, something could be wrong with the CSV file itself, so let’s take a look at the CSV file in Notepad ++ one more time.
Check the CSV file itself
As soon as I quickly glanced through the column header, there is something that caught my attention. The Line Separators seem to appear in the middle of the column headers, which would mess up how MySQL interprets the headers. So let’s make it right by removing the redundant Line Separator. I also decided to simplify column names to make it easy to refer to the column in subsequent SQL queries.

Yay!!! After amending the column headers, the error message is resolved. But before proceeding any further, don’t forget to review the data type of each column and adjust accordingly if needed. If all is good, then let’s import the data into MySQL Workbench, ready to rock and roll.
4. Perform Exploratory Data Analysis
Let’s start with a simple exploratory data analysis to get to know a little bit more about our dataset. As with every exploration, I believe it’s important to keep an open mind. Therefore, I will let my mind go wild with questions about the data for 1 hour.
Question: What is the size of the table? (a.k.a how many rows and columns?)
SQL Queries
There is no need to write any query. Instead, I decided to select the table name, right-click and select Table Inspector to have a quick look.

And since we are here, I thought it would be convenient to glance through the data type of each column as well.
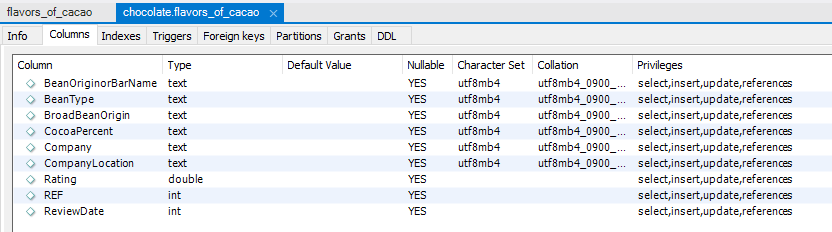
Observations
- The data contains 1793 rows and 9 columns. The size is relatively small and the structure is simple. We expect no performance issue when querying the data even without limiting the number of outputs.
- The column “CocoaPercent” is text, which is unexpected for a numerical value. So let’s keep this in mind as we might need to correct the data type at a later stage.
Question: What does each row of data look like?
SQL Queries
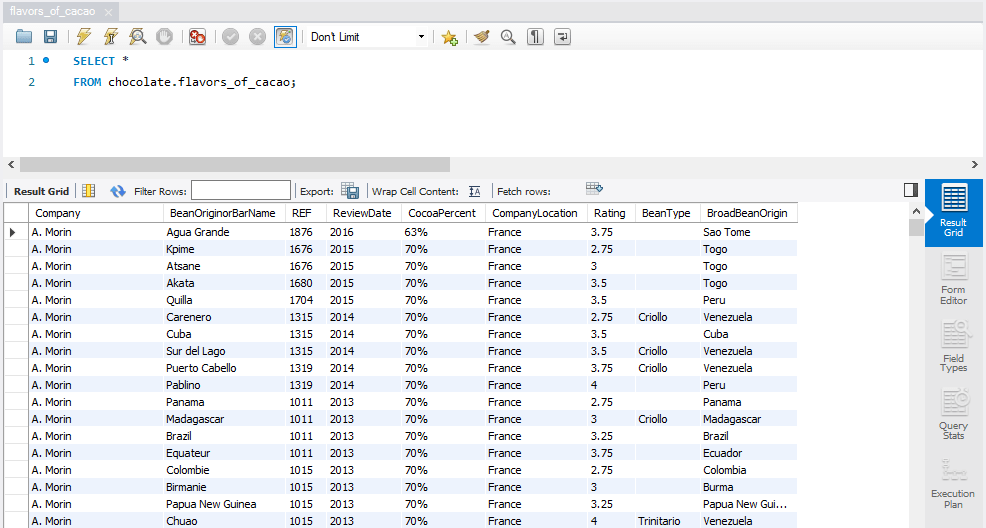
Observations
- The Rating indicates how good or how bad each chocolate bar is based on each review.
- The ReviewDate indicates that the data contains ratings obtained across various years instead of a single year.
- A few variables which may or may not influence the rating are the Company, BeanOriginorBarName, CocoaPercent, CompanyLocation, BeanType and BroadBeanOrigin.
- BeanType columns have many null values, which will require cleansing subsequently if we consider it as a key criterion to select chocolate bars.
Question: What is the distribution of products across the ratings?
SQL Queries
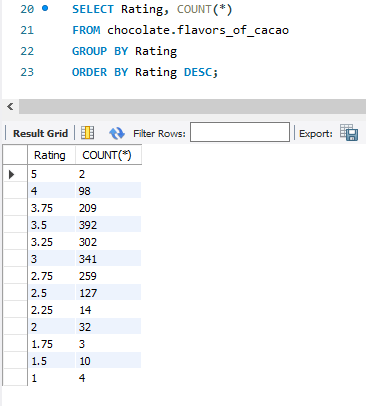
Observations
- None of the rows has any null value for ratings. All ratings lie within the expected value range between 1 and 5.
- The ratings are decimal numbers. To make it easier to understand, we can group them based on a 5-scale rating definition (which are Elite, Premium, Satisfactory, Disappointing and Unpleasant).
Question: How can I group them into 5 categories, including Elite, Premium, Satisfactory, Disappointing and Unpleasant?
SQL Queries
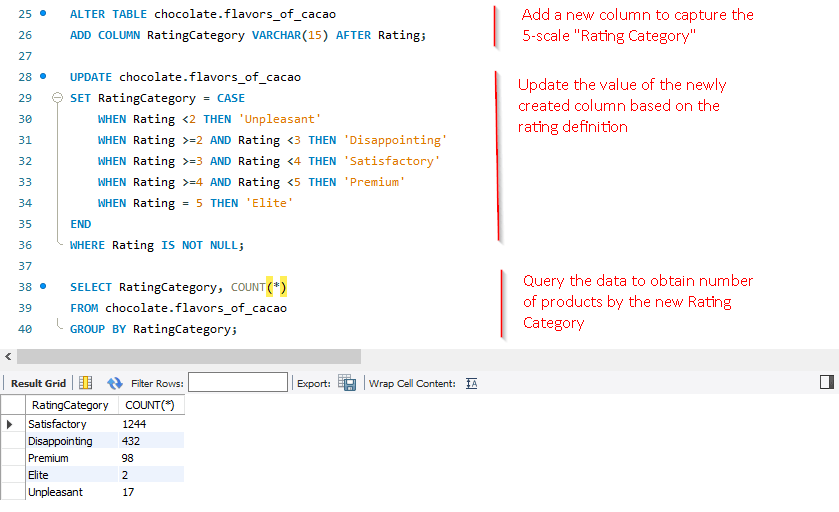
Observations
- Among products in the dataset, there are 2 elite ones that I want to take a closer look at. Also, there are 17 unpleasant ones which I also want to know to avoid at all costs.
- When dealing with the count of products, I can’t help to wonder whether our dataset has any duplicated rows.
Question: What are those elite chocolate bars to look for?
SQL Queries

Observations
- Both elite bars belong to Amedei, an Italian company. They are made of 70% cocoa percent from Trinitario or Blend cocoa beans.
Question: What are those unpleasant ones to avoid?
SQL Queries
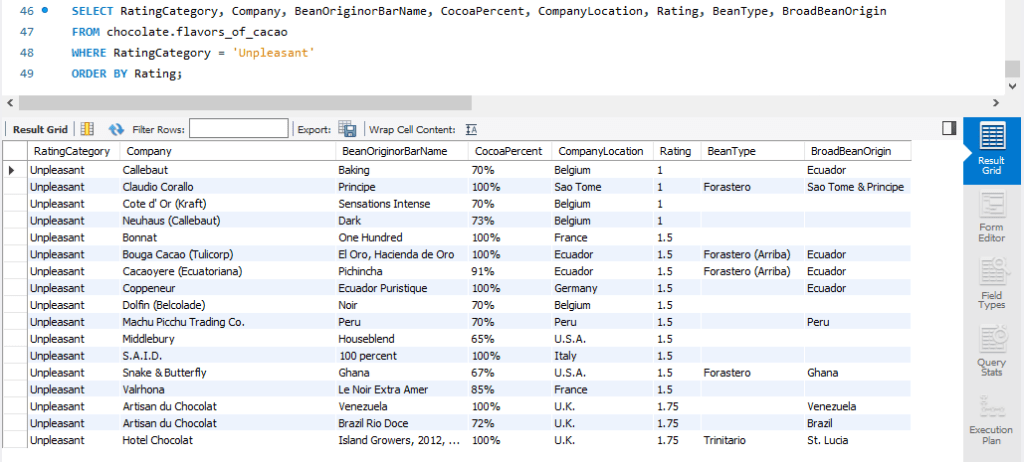
Observations
- The above list features 17 unpleasant chocolate bars that I should avoid purchasing. They are simply a no-no.
- Looking at the list, I am quite surprised to see 4 out of 17 worst bars manufactured by companies in Belgium. After all, being marketed as “Belgian chocolate” seems to be such a popular branding tactic.
Question: Are there any duplicated records in this dataset?
Given that there is no clear-cut primary key, we will have to assess the context and propose a set of attributes that define a unique rating record.
Theory 1. A unique chocolate bar is defined by a combination of Company and BeanOriginorBarName.
SQL Queries
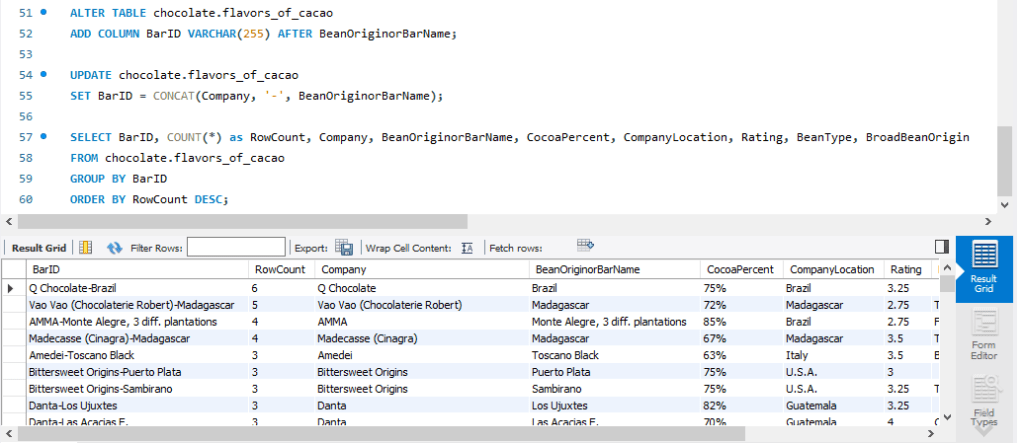
Based on the above result, there are multiple rows for a combination of Company and BeanOriginorBarName. For example, there are 6 rows related to Q Chocolate with Brazil being the BeanOriginorBarName. At this moment, I can’t be sure whether:
- These 6 rows are duplicated
- OR Our theory about what attributes define a unique chocolate bar is missing something.
So let’s take a closer look at these 6 records to understand what is going on.
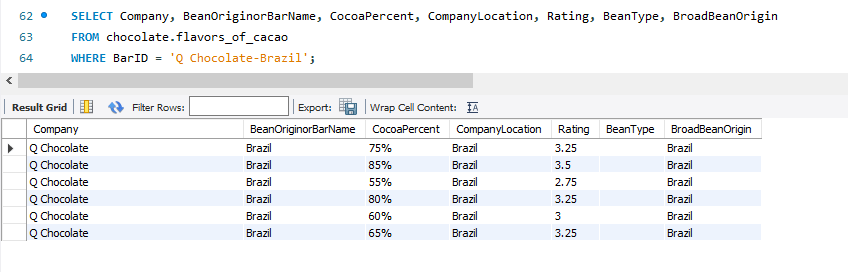
From the above screenshot, I can see that these 6 rows of data show 6 different bars with varying CocoaPercent. This makes absolute sense since bars with different cocoa percentages are marketed as different products and carrying different taste profiles. Hence, our theory about what defines a unique row is missing the CocoaPercent. Let’s adjust our theory and check again.
Theory 2. A unique chocolate bar is defined by a combination of Company, BeanOriginorBarName and CocoaPercent.
SQL Queries

Based on these results, we still have 4 suspicious rows to investigate whether they are duplicated or not.

Upon taking a closer look, 2 rows related to Milcreek Cacao Roasters are not duplicated because are different review taken place in 2 different years. 2 rows related to Tejas aren’t duplicated either because Bean Origin from Mexico and Brazil could carry different taste, quality and could be rated differently.
Observation
- There is no duplicated record in this dataset. The dataset’s primary key should be a combination of Company, BeanOriginorBarName, CocoaPercent, ReviewDate and BroadBeanOrigin.
- To choose the next chocolate bar to try, we can consider 4 aspects of the product.
- Company: Name of the company manufacturing the bar
- BeanOriginorBarName: The specific geo-region of origin of the cocoa beans
- CocoaPercent: Cocoa percentage (darkness) of the chocolate bar
- BroadBeanOrigin: The broad geo-region of origin of the cocoa beans
Question: Are there any rows with null Company?
SQL Queries
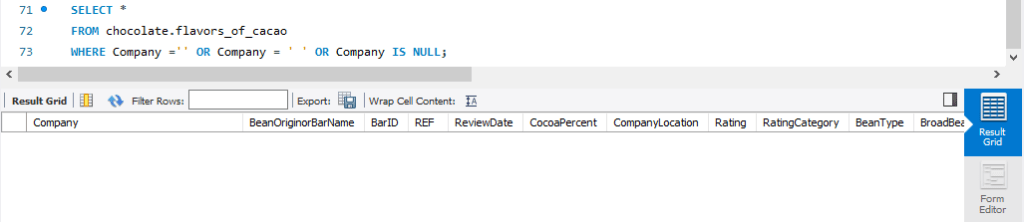
Observation
- As we apply similar queries, there is no null value found for Company, BeanOriginorBarName, CocoaPercent and BroadBeanOrigin.
- Although BeanType is a potential criterion to select a good chocolate bar, the dataset has 888 rows with null BeanType (which is almost 50% of the records). Therefore, we will not rely on this value for further analysis.
Question: What is the range of values for CocoaPercent?
SQL Queries

Observation
- CocoaPercent ranges between 42% and 100%.
Question: How many unique companies are included in the dataset?
SQL Queries
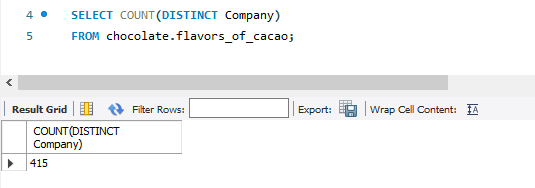
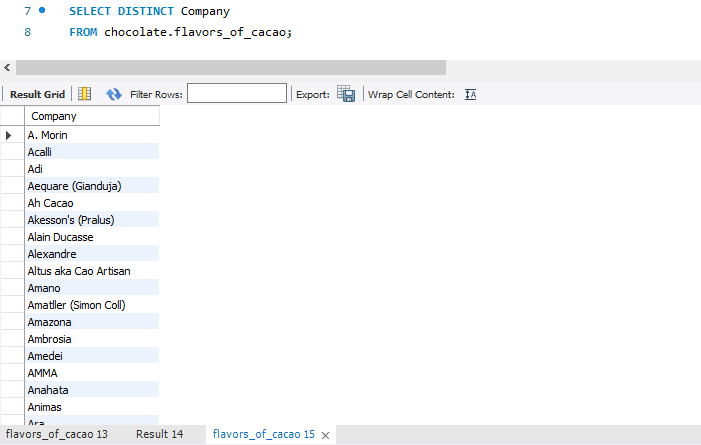
Observations
- There are 415 companies included in the dataset.
- A few familiar chocolate companies caught my eye. By the way, the brands mentioned below are completely unsponsored. Just some exciting comments from a hardcore chocolate fan.
- Lindt & Sprungli: This is the company which taught me how amazing dark chocolate is with sea salt
- Green & Black’s: I discovered this brand when I came to Sydney and it has been one of my all-time favourite ever since. Both the Sea Salt bar and Mint bar are yum!!!
- Valrhona: My go-to option when I have to pick up something quickly in Changi Airport as a gift. Love the packaging.
- Whittakers: I see this all the time in normal supermarkets in Singapore and Australia.
- But man, there are so many other brands and varieties that I have never seen and would love to try. So let’s aim to shortlist a bucket list for must-try dark chocolate.
5. Clean the data (OR Why I think we don’t have to clean this dataset?)
Since the data doesn’t contain duplicated values and null values for important attributes, there is no need to deal with incompleteness and duplication.
When I first thought about this dataset, here is a mistake I have made, so just want to point it out there.
My idea: Considering that we want to select a good chocolate bar, we should focus only on “Premium” or “Elite” bars. Hence, let’s drop all other rows which belong to the other 3 rating categories (i.e. Satisfactory, Disappointing and Unpleasant).
Why is it a bad idea? If we do that, our dataset will be skewed and biased because all bad products are screened out. Imagine if we decide company ABC is the best brand to buy because we ONLY look at the company’s best products, and we happen to pick a chocolate bar which was rated pretty bad (and was removed from the dataset), how would we feel?
All in all, I think it’s a relatively clean and simple dataset to deal with. So let’s keep it simple and leave the data cleansing for other dirty datasets in subsequent projects.
6. Find insights
Question: Does a higher cocoa percentage mean a higher rating?
SQL Queries
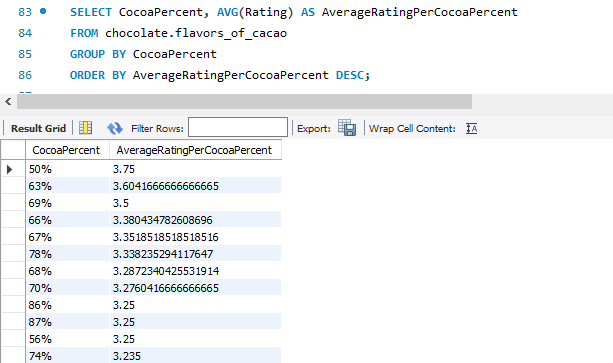
Insight
A higher cocoa percentage does NOT mean a higher rating. Those chocolate bars with 90% cocoa or above has a much lower average rating as compared to those with 60-70% cocoa.
Question: What are the Top 10 companies with the highest average ratings? Where are they located?
SQL Queries
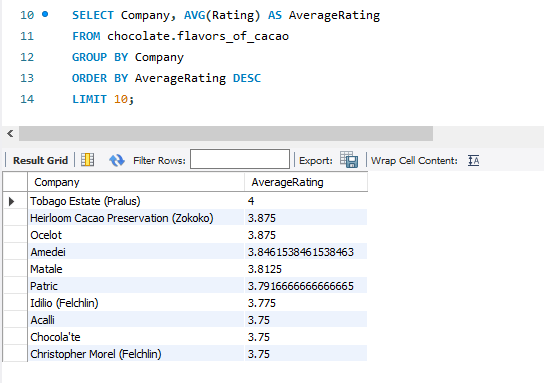
Insight
- The French should be so proud as Tobago Estate (Pralus) has the highest average rating, but who dare to argue with their obsession for gourmet food.
- The U.S.A. is blessed with 4 out of 10 top companies with the highest average ratings. Hmm, how I wish I can travel to U.S.A. and try out some of these amazing products.
- As I am currently living in Sydney, I would love to try out the Matale chocolate. Unfortunately, I have never seen them around in nearby retail stores and Google also doesn’t help. Not sure whether they are still operating. How sad!!!
Question: Considering the top 5 companies with the highest ratings, what chocolate bars with a rating of Premium or Elite?
SQL Queries


Insight
- This list would be my bucket list for the chocolate to try if I ever can purchase from online or retail stores.
- It is worth notice that not all Top 10 companies have their products featured on this list. This can be explained by looking at specific products. For example, Acalli, Chocola’te and Christopher Morel (Felchlin) made it to the Top 10 companies with the highest ratings of 3.75. As they do not have any product which rated 4 or above, the above bucket list of Premium or Elite rating doesn’t feature any of their products.
Question: What are the top “Made in Australia” chocolate bars I can buy?
SQL Queries

Insight
- Although I have no luck finding Matale chocolate, Smooth Chocolator does have a website for online order. Guess what I will do after completing this fun project? Hehehe.
Question: What are those other “Made in Australia” chocolate bars with satisfactory quality that I can buy?
SQL Queries
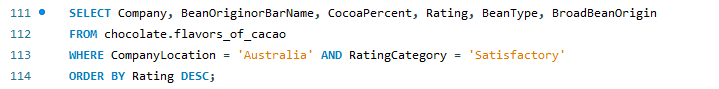
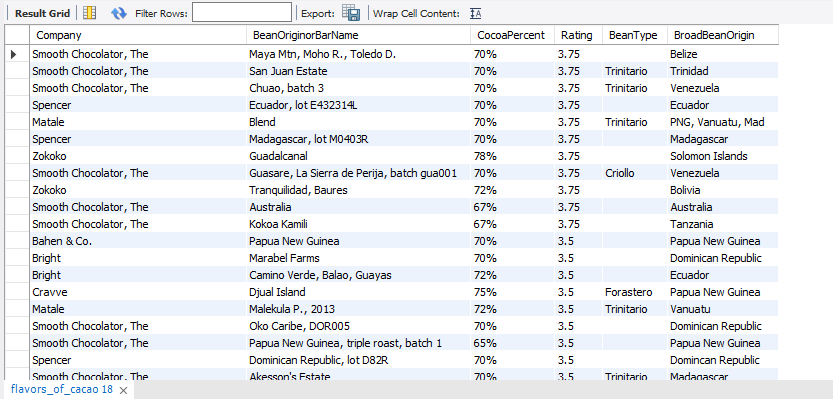
Insight
- Here in Australia, I feel blessed with 37 other satisfactory chocolate bars to choose from, if for whatever reason I can’t get my hand on those “Premium” Smooth Chocolator bars.
- It is also interesting to note that a well-known brand such as Haigh did not score very well as compared to other smaller chocolate manufacturers that I have never heard of before.
7. Wrapping Up
As our exploration for the flavour of chocolate with MySQL Workbench has come to an end, there are 3 key takeaways from the entire exercise when it comes to choosing your next chocolate bar.
- Don’t go crazy with high cocoa percentage, thinking that it’s gonna taste nicer. The best range of cocoa percentages to go for is between 60 and 70%.
- The below picture shows the bucket list you might be keen on trying if you are a also fan of chocolate.
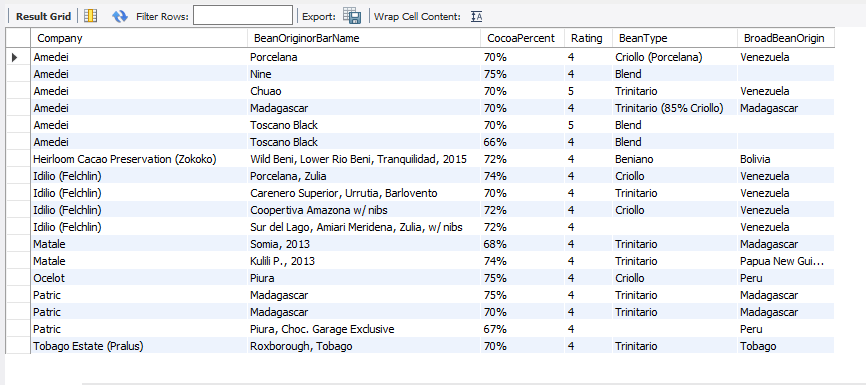
- If you are living in Australia, there are plenty of quality chocolate bars to choose from. However, according to expert ratings, avoid mainstream well-known brands but do try out artisanal products from smaller companies which offer Australian-made high-quality dark chocolate. Those are hidden gems waiting to be discovered.
Hope you have enjoyed this sweet chocolatey tutorial for MySQL Workbench. Cheerio, see you next time!
