Designing databases presents a conundrum: How are you supposed to design a database when you’ve never designed something similar?
Like, how are you supposed to know what works and what doesn’t when all the tips and tricks you Google are slightly different or worst still, contradicting one another? Or how are you supposed to avoid costly mistakes that could impede the performance when you are building everything from scratch? Here are 8 things you can do.
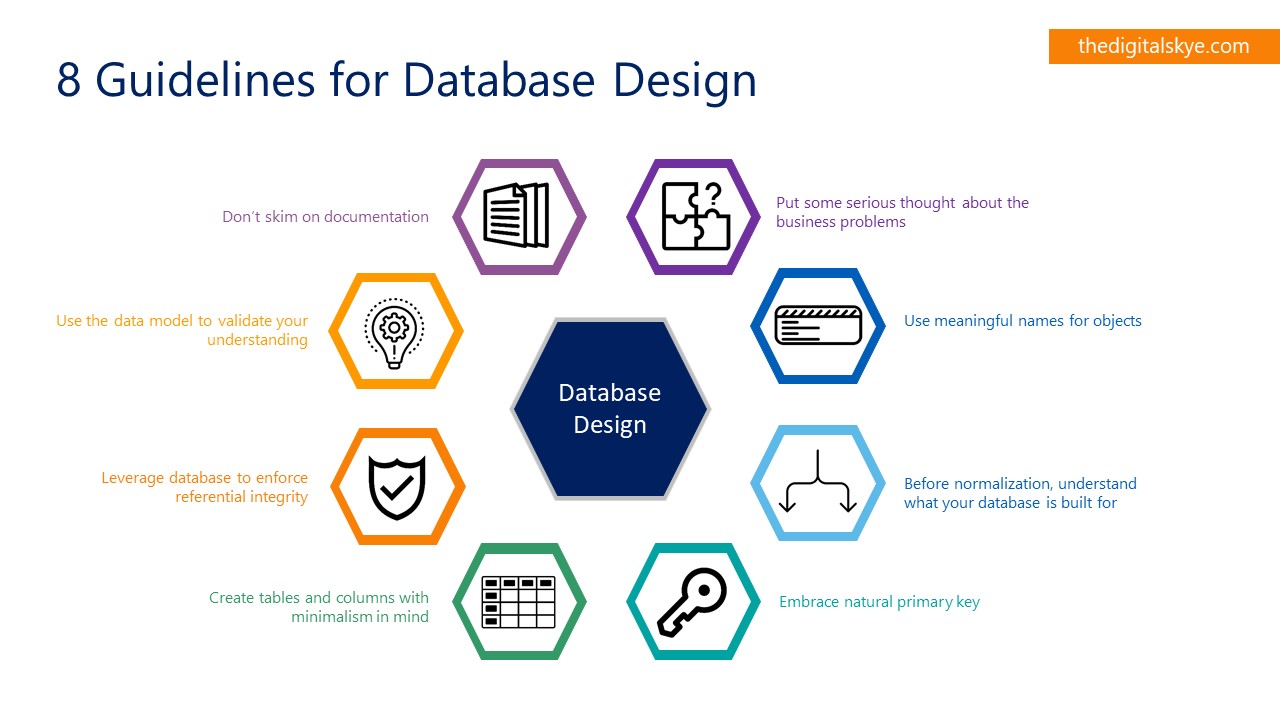
1. Put some serious thought about the business problems
If you should take away one thing from this post, it should be this one. Businesses do not spend money to create a database just to get normalisation, index, query performance and optimisation right. They invest a lump sum because there exists a crucial problem, and the problem has to be solved. This means at the end of the day, none of those fancy database design techniques matters if the problem has not been solved.
So before designing anything for the database, I think it’s crucial to ask yourself 4 questions.
- What problem is the business hoping to solve with the database (or the application supported by the database)?
- Have I fully understood what tasks need to be carried out by ALL business users who will interact with the system?
- Can I confidently list down what data is required to enable business users to carry those tasks?
- How are exceptions and irregularities dealt with in real-life?
And yes, I know it’s challenging to become experts in real-life operations, especially when we all have tight deadlines to meet. But it’s not good enough to stop at a partial understanding and rush to deliver something either. For me, as a professional, this fundamental reminder means to commit the time needed to ask enough questions, gather information, and put some serious thoughts into the problem, the approach, the tasks, the desired solution and the responsibility that comes with my judgment. We all want to be proud of creating a robust and thoughtful solution instead of building a cumbersome monster, am I correct?
2. Use meaningful names for objects
Before creating the first draft of your database model, getting some basic ground rules for naming objects ready will save you heaps of time to communicate with other team members, business users and stakeholders.
But don’t waste one entire week to agree on naming convention either. Someone just has to propose a set of rules, send it out to everyone and finalise it within a meeting. Keep it short and sweet (less than half an A4 page is ideal) because no one likes the feeling of referring to long documentation. Exceptions will arise as new fields and tables are identified, but those specific scenarios could be discussed during the daily team catch-up.
If you need some inspiration, here are some basic rules that I have been using. You might follow a totally different set of rules, and that’s perfectly fine. The most important thing to keep in mind is that names are meant to communicate certain meanings, so make them meaningful and consistent for the business users.
- Use meaningful names that help to communicate the context for business users
- Singular noun, all lowercase words separated by underscores (to help speed typing and avoid mistakes if you are dealing with case-sensitive MySQL)
- Avoid special characters (include spacing) and database reserved words
- Use full words – no abbreviations unless they are necessary and routinely used by business users
- Avoid column and table having the same name (to avoid confusion while writing query)
- Singular column primary key: id
- Single column foreign key: <referenced_table>_id
3. Before normalization, understand what your database is being built for
Normalisation is regarded as one of the best design practices to adhere to. But is it true all the time? Well, think again.
People don’t build databases for the sake of having them exist in isolation. Databases are built to capture and process data for a specific application. To normalise or not depends on whether the application is transactional and analytical.
Databases built to support transactional application needs to ensure the data is free from logical inconsistencies during insertion, update and deletion. For example, a casual staff has a fixed hourly rate. Normalise (i.e. splitting the monthly salary records and the pay rate into 2 separate tables) eliminates the need for accountants to enter casual staff’s hourly rate every month. Fewer things to enter means fewer human errors, which eventually translates to more consistent and accurate data.
Databases built to support analytical application needs to create aggregations and calculations across multiple tables as quickly as possible. But each join between 2 tables takes time. And it’s not a fun task when we have to process millions of transactional records at the same time. Therefore, we have to minimise the number of joins required to query our data, which means normalization doesn’t sound like a good idea anymore in this case.
So now we know normalization is perfect for transactional applications, yet it could be a nightmare to designed databases for analytical applications. But how do you tell which from which? Here is a quick comparison to guide you along.
| Transactional | Analytical | |
| What does the application deliver? | Improved productivity for end-users through automation | Improved business insights, planning and decision-making for managers and executives |
| Where can you find it? | Enterprise Resource Planning system (ERP)Point of Sale (POS) systemAirline ticket booking systemLibrary Management System | BI & Analytics systemData warehouse |
| How does the database intend to support the application? | To capture, update or delete individual business tasks | To analyse, report or forecast business performance by creating aggregations and calculations from multidimensional data |
| What are the defining characteristics of the database? | Handle a large number of transactionsMainly use INSERT, UPDATE, DELETE commands to capture transactionEmphasise data integrity, consistency, backup and recovery | Handle large volumes of data Mainly use complex SELECT queries to create aggregations and calculationsEmphasise response time to fetch and analyse data as fast as possible |
| To normalise or not? | Normalise | Denormalise |
4. Embrace natural primary key
Database Teacher: Each relational table needs a primary key to avoid duplicated records.
Someone said on a website: The best way is to use an auto-incremental integer field for the primary key.
Naïve me: Okay, I should create an auto-incremental integer field named “id” to be the primary key for every relational table.
Confession time! This is a misunderstanding I used to have until Bill Karwin corrected me through his wonderful book named SQL Antipatterns. Check out that book. It’s one of the most amazing SQL books out there. Meanwhile, here is my summarised explanation about this specific point so that you don’t make the same mistake ever again.
A primary key exists to represent a very important constraint: Each row in a relational database has to be unique. Any entries with the same primary key are duplicated and will be prevented from entering the database. No duplication means no double-counting when reporting business metrics such as the total number of real customers, monthly sales, employee training costs and so on.
| id | article_id | tag_id |
| 1 | 1 | 2 |
| 2 | 1 | 2 |
| 3 | 1 | 2 |
The above table captures the relationship between an article and the tag. For example, this article could have multiple tags associated such as database design, primary key, SQL. But the combination between “article_id” and “tag_id” defines a unique row in this table. The “id” column here is the auto-increment primary key. But does it prevent duplicates from entering the database? No, it doesn’t.
Okay, how about defining a UNIQUE constraint to check that the combination between “article_id” and “tag_id” is unique before inserting a new row? Yes, that’s possible. But then why do we have to use an auto-increment “id” column in the first place?
This brings us to an important guideline: If there exists a column or a combination of columns that can define a unique record based on the natural order of business and satisfy the below lists of conditions, consider using it as the primary key. This works way better than blindly creating another auto-incremented integer “id” column (e.g. surrogate key, GUID) just because someone said so somewhere.
- Unique and not null
- Support indexing
- Unlikely to become duplicated
- Unlikely to be frequently updated
- Compact and contain the fewest possible columns
5. Create tables and columns with minimalism in mind

That is the famous slogan known as “Ockham’s Razor” attributed to William of Ockham, one of the most prominent philosophers during the High Middle Ages. In the database context, we can interpret it as follows: don’t create additional tables or columns ifthat isn’t necessary.
Keep in mind that the more tables and columns a database has, the more complex and expensive the maintenance is. So if you don’t gain any serious advantages other than making life a little harder for yourself, why bother?
But after weighing both the cost and the benefits, if the verdict states that you seriously need to create more tables or columns, then here are some valid suggestions.
- To store multivalue attributes (e.g. multiple phone numbers of a customer, multiple tags to an article, multiple usages for an item): Instead of continuously adding more and more columns on the same table, create a dependent table to store the multiple values in multiple rows.
- To split the table into multiple tables if the table size slows down performance: Instead of splitting the table manually, consider horizontal partitioning to separate chunks of rows into individual parts. In doing so, your table is technically split for improved performance but still appear as a single table for end-users to query easily.
- To allow different users to view different parts of the table based on their access rights: Instead of creating separate tables for different access rights, consider creating a view if the data is changing frequently. However, if the data doesn’t change frequently, opt for a materialised view for better performance as the result of the query is readily stored in the disk.
- To store files, mp3 or long chunks of text: Instead of creating BLOB or TEXT columns on the same table where other simple transactional values (e.g. integer, limited length string), create a separate dependent table that is referenced to the original records via foreign key constraint.
6. Leverage database to enforce referential integrity
On the surface, enforcing referential integrity through foreign key constraints seem to be troublesome as they can conflict with data migrated from another system. Coupled with a looming go-live date, databases are too often treated as a data dump location. And you heard someone suggests, “Keep the database simple and let the application handles the validation rules.” A few people nodded their heads, and all validation rules to ensure all foreign key values reference a valid, existing primary key in the parent table are built into the application.
So what’s wrong with that? Let me give you an analogy. To clean the house, we have two options: a broom and a vacuum cleaner. Which one will you go for? You may choose to grab your broom to clean the house, thinking that it will remove dust and dirt as clean a vacuum cleaner. So you spent 20 minutes to do so while all you need is 5 minutes with a vacuum cleaner. And I bet that some dust will remain under the carpet or in some corners after all of the hard work. When we refuse to let the databases do what they do best, which is to implement referential integrity, we end up making things less efficient and may never get exactly what we want.
And don’t forget applications are implemented, then upgraded or replaced, while the same data tends to live with the business (not so) happily ever after! How many times can we afford to build and rebuild the same validation rules in all sorts of applications?
Of course, there are databases out there that don’t support foreign key constraints such as MySQL’s MyISAM storage engine. Unfortunately, we don’t have a choice in such a case. But if the database can support foreign key constraints, then letting it handle what it does best. This will save us time and effort to do additional coding to check for referential integrity. The fewer codes to write in our application, the fewer bugs to fix and the simpler it is to maintain the entire solution. Who doesn’t love a win-win situation for everyone?
7. Use the data model to validate your understanding
Let say you have created the first draft of the data models, or you have lost count on how many times you have made changes to it, yet how do you know whether you have covered everything? Well, the data model itself might provide you with so many clues. The only thing we have to do is to start looking at the model and ask all sorts of questions about the entities and relationships.
But what questions should you ask? Let me share with you some questions that I usually ponder as I use the data model to learn and review my work.
| Questions to ask | Example |
| How do I define this entity? | How do I define a sales lead? People registered their contact details with the company or anyone that contacted the company? |
| How do I differentiate between entity A and entity B? | How do I differentiate between part-time staff and full-time employees? Should I keep them as 1 or 2 entities? |
| Can it be 0 or must it have at least 1? | Can a customer have 0 or at least 1 sales order placed? How about customers that have not placed any purchase yet? |
| Might it occasionally be 2 or more? | Can a student enroll in a unit twice or more if he fails the unit and has to retake again and again? |
| Do I have to keep track of history? If yes, how? | An employee can only borrow one laptop at a time and a laptop can only be loaned to one employee. However, if the same employee requests to borrow the same laptop again and again, how do I keep track of previous borrowings? |
| How do entities involved in a many-to-many relationship relate to each other? | Many employees can work on a project and an employee can work on multiple projects. How do employees and projects relate to each other? Do I need to create an intermediate table (e.g. project_assignment) to capture the relationship? |
At the beginning of this post, I have emphasised the importance of understanding the problem before getting started. But learning about the problem doesn’t stop as we have come up with the data model because the first draft is never gonna be perfect. Therefore, I would suggest anyone who is designing a database to start looking at the model and ask many questions. The answers to these questions might result in anything between minor changes and a major overhaul to the data model, but don’t fret. Let’s embrace the changes and the iterative process. I promise you can conquer it and you will emerge from the other end with grace, knowledge and a stronger sense of purpose to implement a solution with fewer regrets and frown faces.
8. Don’t skim on documentation
Ah, documentation, the arguably most boring and time-consuming task of the year! Well, having written countless project documents, I get where you are coming from. But let me share how I managed to push back my excuses.
- I don’t have time now for documentation. Errr, well then will I have time later to sit through many meetings with the team to convey how the database should be created during the implementation process?
- Our team worked very closely together. My teammates know exactly what I am working on. Ah yes, but can they read my mind and understand exactly why I did what I did? And don’t they have their own challenges to remember and prioritise?
- I am always available for Q&A if anyone needs to know something about the design. But can I be sure to remember every detail, especially when changes are made constantly throughout the design process? I know very well that I can’t.
- The design is standard and self-explanatory. Really? Have I tried asking someone to comprehend it on his or her own? Where is my sense of value-added service and kindness to others?
But what should be documented? With time and cost constraints, it’s impractical to record our design diary. So below is what you might want to include in the database design depository.
- Entity-Relationship Diagram showing final tables, columns and relationships
- Definition/ Meaning of each data columns
- Business rule specification mapped to database constraints and/ or triggers implemented
- View diagrams and specifications
- Notes compiled for decisions made during the design process
- Data samples gathered during analysis
Wrapping Up
Don’t forget the devil is in the details when designing even the simplest database. It’s perfectly okay to feel frustrated after making so many changes. But remember you are helping a person, or many people, to solve a crucial problem. And if you have been chosen to do the job, I am sure you have it in yourself to make it happen.
I sincerely hope you had enjoyed reading the blog post as much as how I enjoyed researching and writing about the topic. If you find the content might be useful for someone else, please share. Thank you for visiting my blog and till next time!
