HyperLogLog (HLL) is an algorithm that estimates how many unique elements the dataset contains. Google BigQuery has leveraged this algorithm to approximately count unique elements for very large dataset with 1 billion rows and above.
In this article, we’ll cover 2 points.
- What’s HLL?
- How does HLL compare with other methods?
What’s HLL?
The HyperLogLog algorithm can estimate cardinalities well beyond 10^9 with a relative accuracy (standard error) of 2% while only using 1.5kb of memory.
HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm by Philippe Flajolet et al.
HLL is one of many cardinality estimation algorithms which are all invented to solve one problem: how to count the number of unique elements as fast and accurately as possible. As you might have guessed, cardinality means the number of unique elements in a dataset with duplicated entries.
These algorithms are extremely useful when you have a very large dataset, far too large to sort and count how many unique entries within seconds. Below are a few real-life use cases.
- Detection of network attacks (e.g. Denial of Service) by counting the unique header pairs of data packet transmitted in various time slices
- Estimate the count of unique records in Redis, AWS Redshift and Druid datasets
- Count the number of unique users during a time period for real-time activity reports of mobile apps
HLL is the product of various enhancements of the Flajolet-Martin algorithm introduced by Philippe Flajolet and G. Nigel Martin in 1984. Since then, Google has adopted and improved on it to become HyperLogLog++ functions. Apart from Google, many other technology platforms have implemented their own data structures based on HLL. Nevertheless, they all share the same basic rule.
If all numbers in the set are represented in binary and let n be the maximum number of leading 0s observed in all numbers, 2n is the estimated unique count of numbers.
In short, with HLL, we trade off some accuracy to get the job done faster. But how much faster and at the expense of what level of accuracy? Let’s run some experiment in Google BigQuery.
How does HLL compare with other methods?
Let’s start with a big dataset. I am using the Wikipedia dataset which is available via Google BigQuery Public dataset. To extract only 2020 data, I have created a permanent table with the below query.
# Create a table containing all hourly views per Wikipedia page in 2020
CREATE OR REPLACE TABLE
`bigquery-301504.wikipedia.view_2020` AS
SELECT
*
FROM
`bigquery-public-data.wikipedia.pageviews_2020`
WHERE
DATE(datehour) < "2021-01-01"
AND DATE(datehour) > "2019-12-31";This large table (2.24TB with more than 5 billion rows) contains the number of views for each Wikipedia page title every hourly in 2020. You can take a look at the schema below.

Let say we want to find out how many unique titles viewed every month in 2020, here is the simplest SQL query we can write.
Query
# DISTINCT method
SELECT
EXTRACT(MONTH
FROM
datehour) AS month,
COUNT(DISTINCT title) AS title_count
FROM
`bigquery-301504.wikipedia.view_2020`
GROUP BY
month
ORDER BY
month;Result
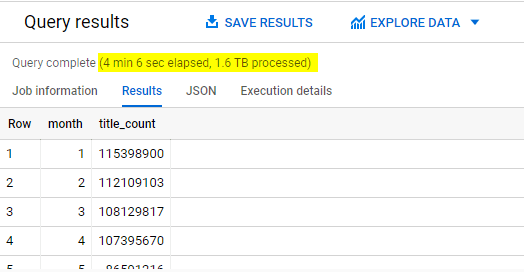
When using DISTINCT function, Google BigQuery needs to keep track of every unique date it has ever seen. Hence it took more than 4 minutes to run this query.
Luckily we can go faster if we are willing to trade off some accuracy. There are 2 options to arrive at an approximate count.
Option #1 – APPROX_COUNT_DISTINCT
Query
# APPROX_COUNT_DISTINCT method
SELECT
EXTRACT(MONTH
FROM
datehour) AS month,
APPROX_COUNT_DISTINCT(title) AS title_count
FROM
`bigquery-301504.wikipedia.view_2020`
GROUP BY
month
ORDER BY
month;Result

Way better, but can we push it a little harder? Yes, we can.
Option #2 – HLL
Let’s see how we can use HLL to solve the same challenge of counting unique titles viewed every month.
Query
# HLL method
WITH
hll_count AS (
SELECT
EXTRACT(MONTH
FROM
datehour) AS month,
HLL_COUNT.INIT(title) title_count
FROM
`bigquery-301504.wikipedia.view_2020`
GROUP BY
month)
SELECT
month,
hll_count.
MERGE
(title_count)
FROM
hll_count
GROUP BY
month
order by month;Result
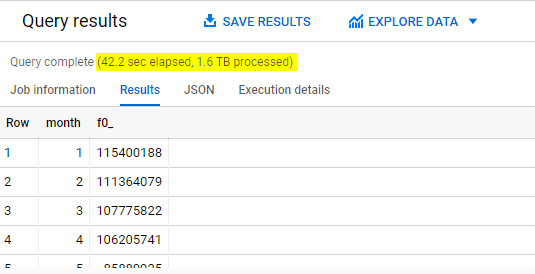
The moment we gave up even less than 1% accuracy, we speed up the query by 6 times. Of course there will be scenarios whereby accuracy is required such as financial reporting or scientific research calculations. Otherwise, both APPROX_COUNT_DISTINCT and HLL will come in handy if performance is more important than absolute accuracy.
Updated on 14 Jan based on Mosha Pasumansky’s kind feedback:
Although the queries for APPROX_COUNT_DISTINCT and HLL look different, it’s worth to note that both utilise the same HLL algorithm. Since the second method is more complicated, you might want to use APPROX_COUNT_DISTINCT to keep the code cleaner and more readable.
Parting Thoughts
If you are interested in learning more about the evolution of HLL, do check out the following papers.
Probabilistic Counting Algorithms for Database Applications
LogLog Counting of Large Cardinalities
HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm
That’s all I have for today. Thank you for reading and do let me know if you have any feedback. Take care and stay safe everyone!

APPROX_COUNT_DISTINCT uses HLL+ as implementation, so both methods do exactly the same computations
LikeLike
Hi Mosha, thank you so much for correcting my mistake. I am so grateful. Update has been made to the blog post accordingly. Have a fabulous day!
LikeLike