

Metadata! I bet you might have heard this term before and may have asked yourself what it is and why it is important. Let’s explore this concept with Google BigQuery.
In this article, you’ll discover:
- What is metadata?
- Why query table metadata in Google BigQuery?
- How to query table metadata with INFORMATION_SCHEMA and TABLES?
What is metadata?
Many sources define metadata as “data about data”. But I personally find it too vague and difficult to understand. So here is my attempt to define metadata in layman’s terms.

Why query table metadata in Google BigQuery?
Imagine we were given a huge dataset containing many tables in BigQuery, which one should we query? How do we identify which tables are the most updated? When was each table created? What columns are present in each table? Believe it or not, all of these questions can be answered with metadata.
And when it comes to query table metadata, there are many potential solutions, ranging from simple view in Google Cloud Console to more complex client libraries. But here are the 3 simplest and least technical solutions to begin with.
The first solution is looking at a Data Catalog, which is a collection of metadata designed to help us search through all available tables, evaluate their quality and usefulness, then access whatever tables we deem suitable for our analysis. This is probably the easiest way to figure out which specific tables we should query. But what if we don’t have a Data Catalog readily available at our fingertips. How now, brown cow?
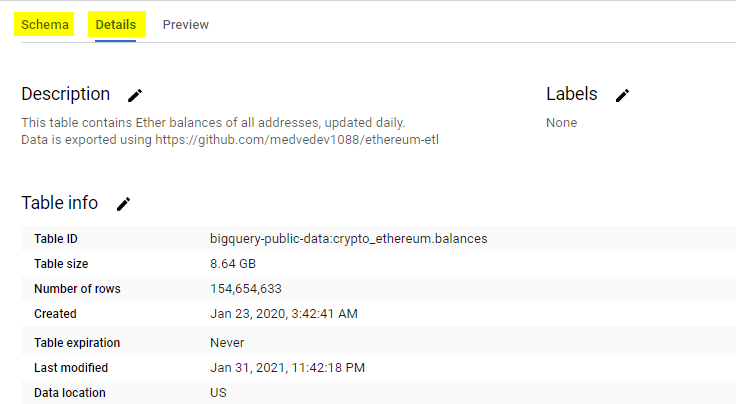
The second option is readily available in Google Cloud Console as shown above. Yes, I am talking about the “Details” and “Schema” tabs related to each table under BigQuery. Nevertheless, this solution will seriously trigger headaches if we have to click through dozens of tables (or even hundreds) one by one. There must be a better way, right?
The third solution is here to save the day. Guess what? We can easily obtain all table metadata across multiple datasets using either INFORMATION_SCHEMA or TABLES meta table, all with easy SQL queries right from the familiar BigQuery interface. And that’s what will be covered in the next section. Drum Roll, everybody! Let’s dive right in.
How to query table metadata
Overview about all tables
There are 2 options to obtain an overview of all tables within a dataset. Both options are listed as follows.
Option 1. INFORMATION_SCHEMA views
INFORMATION_SCHEMA is a series of views that provide access to metadata about datasets, routines, tables, views, jobs, reservations, and streaming data.
From Google Cloud
Before writing our first query, it’s crucial to keep in mind the following 2 points.
- Queries against INFORMATION_SCHEMA views aren’t cached and will incur data processing charges (for 10MB) or consume the BigQuery slots, depending on the pricing related to your project.
- INFORMATIONS_SCHEMA queries must be written in standard SQL syntax.
List all tables
Let’s begin exploring the Ethereum Blockchain dataset in BigQuery public data. We will start with 2 simple questions: How many tables are there in the dataset? What are those tables?
We can easily obtain the answer by running a simple query.
# List all tables and their creation time from a single dataset with TABLES view
#standardSQL
SELECT *
FROM `bigquery-public-data.ethereum_blockchain`.INFORMATION_SCHEMA.TABLES;
Looking at the query results, first and foremost, there are 14 tables under this dataset. Each table corresponds to one row, together with the below columns. Here is a quick overview of what each column means according to GCP documentation.
- Project ID of the project containing the dataset
- Dataset’s name of the dataset containing the tables and/or views
- Names of all tables belonging to the specified dataset
- Indicator whether the table is a normal BigQuery table (a.k.a BASE TABLE), a view, a materialized view or referencing an external data source.
- Indicator whether the table supports SQL INSERT statements
- The value is always NO
- Datetime of when the table is created
List selected tables within a dataset with WHERE clause
This time we are only interested in obtaining the table name and the creation time of BigQuery tables in the Ethereum Blockchain dataset containing token information. Well, let’s add a relevant WHERE clause to filter the result that we want. Tada! Below is the query and the result.
# List metadata from selected tables with WHERE clause
#standardSQL
SELECT
table_name,
creation_time
FROM
`bigquery-public-data.ethereum_blockchain`.INFORMATION_SCHEMA.TABLES
WHERE
table_type = "BASE TABLE"
AND table_name LIKE "%token%";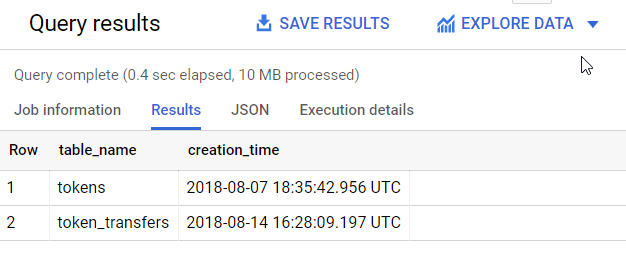
Option 2. TABLES meta table
So far so good, but it’s clear that the INFORMATION_SCHEMA view alone isn’t enough to help us identify the largest table based on size or the most updated table based on “last modified time”. Don’t fret, peeps! Because in each dataset, there is a hidden table that contains even more metadata about each table. Luckily this hidden table is accessible at <projectname.dataset.name>.__TABLES__
Important Note: You need to type 2 underscores on each side of “TABLES”.
Let me introduce you to a very useful query that leverages this TABLES meta table to obtain the size, number of rows and last modified time of all tables within our dataset. Definitely a blessing for me to learn this query from a Coursera course by Google Cloud Training. Here we go, everybody!
#standardSQL
SELECT
dataset_id,
table_id,
# Convert size in bytes to GB
ROUND(size_bytes/POW(10,9),2) AS size_gb,
# Convert creation_time and last_modified_time from UNIX EPOCH format to a timestamp
TIMESTAMP_MILLIS(creation_time) AS creation_time,
TIMESTAMP_MILLIS(last_modified_time) AS last_modified_time,
row_count,
# Convert table type from numerical value to description
CASE
WHEN type = 1 THEN 'table'
WHEN type = 2 THEN 'view'
ELSE
NULL
END
AS type
FROM
`bigquery-public-data.ethereum_blockchain`.__TABLES__
ORDER BY
size_gb DESC;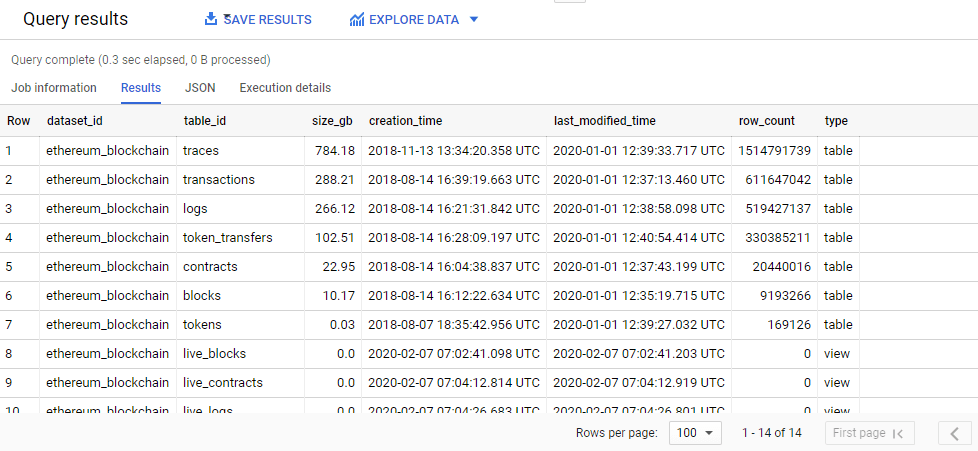
But what if you want to list all tables and their details across multiple datasets? You can use UNION ALL to iterate through each dataset, similar to this query listed in this GCP GitHub.
Zooming into columns
Let’s take a closer look at all data columns in the Ethereum Blockchain dataset. We will discover how many columns are present in each table and identify partitioned or clustered columns.
List all columns
The query can’t be simpler.
# List all columns related to all tables within a dataset
SELECT
table_name,
column_name,
is_nullable,
data_type,
is_partitioning_column
FROM
`bigquery-public-data.ethereum_blockchain`.INFORMATION_SCHEMA.COLUMNS;
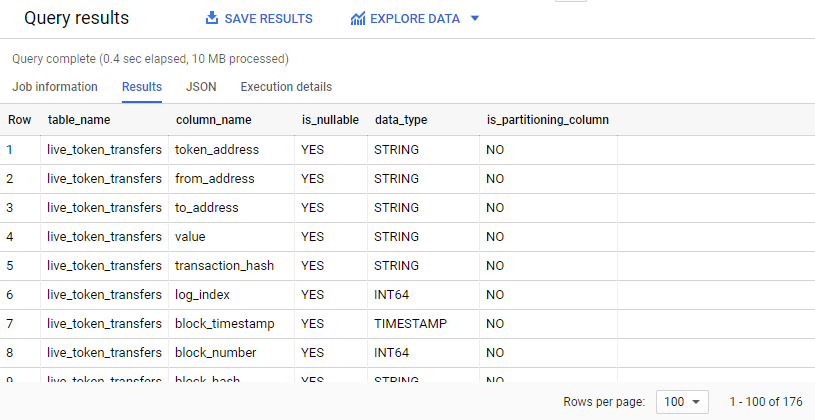
Here I specify 5 attributes in the SELECT clause because I am only interested in getting the column name, data type, nullability and whether the column is used for partitioning. Feel free to give SELECT * a try to see all other attributes containing metadata about data columns.
Filter only timestamp columns used for partitioning
What if we need to identify all timestamp columns currently used for partitioning? Let’s twist the above query to give us what we want.
#standardSQL
SELECT
table_name,
column_name,
is_nullable,
data_type,
is_partitioning_column
FROM
`bigquery-public-data.ethereum_blockchain`.INFORMATION_SCHEMA.COLUMNS
WHERE data_type = "TIMESTAMP"
AND is_partitioning_column = "YES";
Parting Thoughts
The more we work with big data, the shorter time we have to decide which tables are worth our investigation and which ones can be ignored. Although this article barely scratches the surface of what can be done with TABLES meta table and INFORMATION_SCHEMA views when exploring metadata for BigQuery datasets, I hope it could serve at a good starting point. If you are keen on exploring metadata about the dataset, streaming, job and so on with INFORMATION_SCHEMA views, don’t forget to check out GCP documentation.
Thank you for reading. Have feedback on how I can do better or just wanna chat? Let me know in the comments or find me on LinkedIn. Have a fabulous week everyone!
