

Born in the 1980s, about 40 years old and still counting. It’s no other than the data warehouse, which requires some hefty investment, might take years to build. Yet the chance of failure is sky-high. Fast forward to 2021, the data warehouse has been evolving with time and will continue to be the backbone for business insights across organisations all over the world. So what is it? Why do we need a data warehouse in the first place? As a data professional, what do you need to know about data warehouse at the bare minimum?
In this article, you’ll learn:
- The Big Picture: Two Distinct Needs for Data in Business
- Traditional vs Modern Data Warehouse
- EL vs ELT vs ETL vs Change Data Capture: How to Get Data into a Data Warehouse
The Big Picture: Two Distinct Needs for Data in Business
No definition of the data warehouse would be complete without a short narrative regarding how organisational needs for data has evolved around two main purposes.
Data Capture
At the beginning of enterprise data, it all started with the sole objective of capturing transactional data for operational records. Think about all customers’ contact details, sales orders, invoices, payslips and so on. The database was created to serve 2 purposes.
- Record and keep track of business activities quickly and digitally (so that we don’t have to deal with papers flying everywhere and getting lost forever)
- Help business users to complete their day-to-day tasks more effectively (e.g. whether an order has been shipped or how much inventory we are having)
Simply put, focusing on the present and making sure business transactions happen as smoothly as possible was how our world of data used to be.
Data Analysis
However, businesses quickly realised living in the moment wasn’t good enough. New questions arose. How are we performing as compared to last month? Why was there a fall in revenue in the last two quarters? What have our customers regularly complained about since the beginning of the year? The need to capture all operational records is still indispensable, but there is now another equally important objective: analysing historical data for decision-making.
Unfortunately, a database once built to capture transactional data wasn’t suitable to empower management with enough facts and historical insights for making informed decisions. Owing to the vast difference between capturing present records and storing historical data across a variety of data sources for analysis, we need another tool. Thus, born was the data warehouse and the rest is history.
Ten-second takeaway
A data warehouse was born to serve the business need, that is to store historical data from multiple data sources for business insights and decision-making.
Traditional vs Modern Data Warehouse
The Traditional Data Warehouse
The data warehouse is all about creating a single version of truth for historical data from various sources and making it easily accessible, in a usable format and quick to query for business insights. In this way, business analysts and management can quickly undercover trends, patterns or anomalies about business performance and decide on what’s the best thing to do.
Building upon this point, below are 9 key requirements for a traditional data warehouse adapted from Ralph Kimball’s book titled “The Data Warehouse Toolkit”.

The Modern Data Warehouse
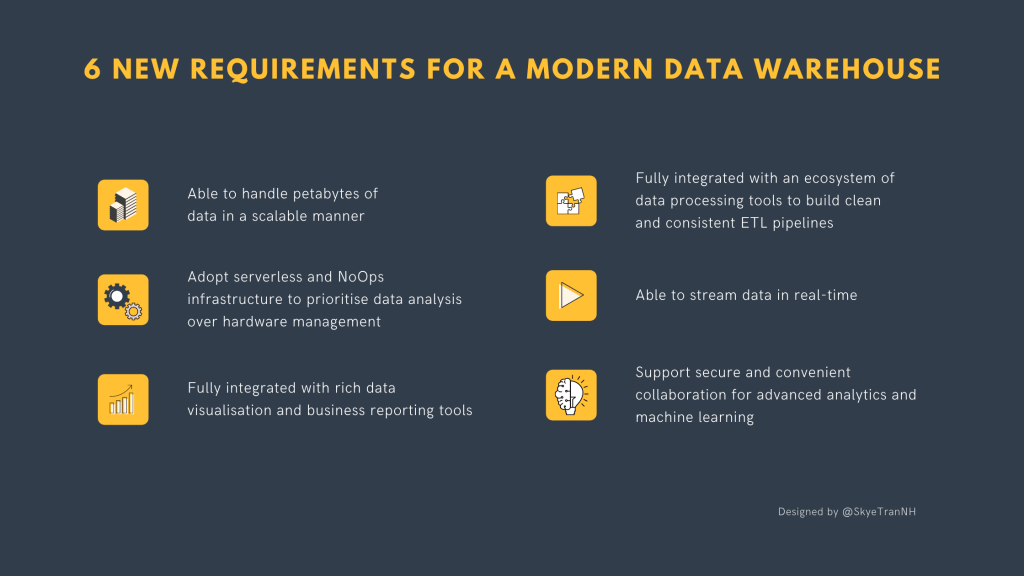
Believe it or not, the architecture for data warehouse was first developed in the 1980s. Entering 2021, three main trends have definitely changed the way businesses treat their data assets and shaped a new generation of data warehouses.
- Big data results in the need to process petabytes of data within a single data warehouse for business insights.
- Cloud computing has created access to near-infinite, low-cost storage with scalable computing power to analyse data with a pay-as-you-go plan.
- The rise of data science and machine learning demands tighter integration among a data warehouse, ETL and data processing tools as well as data visualisation tools to enable near real-time analytics for decision-making.
Unsurprisingly, the concept of a data warehouse also has to evolve to adapt to the new reality. Therefore, apart from those above-mentioned requirements, a modern data warehouse should also fulfill the below requirements.
Data warehouse vs Data lake vs Database
I personally find this article incomplete without quickly touch on the difference between data warehouse, data lake and database. So let’s put things into perspective.
Although all three solutions store data, they serve very different purposes.
- A database records daily transactions that a business makes e.g. an online sales transaction, a new customer subscribing to the newsletter, an item is sold on credit, a hotel room booked via the online reservation system etc. It’s built for processing day-to-day operations instead of analysis for insights.
- A data lake stores all raw, unprocessed data coming from various sources. The data therefore might be either structured, unstructured or semi-structured, might not be in a usable condition while the analysis approach is not yet defined.
- A data warehouse stores processed data in a usable condition at a single location so that business users can easily access it, query it for quick insights and decision-making.
Ten-second takeaway
To continue to empower advanced analytics and machine learning for business insights, a modern data warehouse has to be able to handle petabytes of batched and streaming data as well as tightly integrate with other components of the big data ecosystem in a cloud-based environment.
EL vs ELT vs ETL vs Change Data Capture: How to Get Data into a Data Warehouse
As much as we wish, data from various sources doesn’t just magically transform itself into a clean and usable format, then consolidate itself into a single, centralised location. To have good data in a data warehouse, we say the data needs to be transformed step-by-step. And the series of steps to polish raw data from multiple data sources to useful information in the data warehouse is called data pipelines.
Important Note: Data pipelines are always modeled as directed acyclic graphs (DAG), which flow from one stage to another but never loop back to a previous node or to itself.
We would explore 4 common patterns in data warehouse pipelines as follows.
Extract and load (EL)
EL is probably the simplest data pipeline since no data transformation is involved. This type of data pipeline is only appropriate when the following two criteria are fulfilled.
- The schema of the data sources and data warehouse is the same.
- The data is absolutely clean and readily available in a useful format for ad-hoc queries.
In reality, apart from doing a batch load of historical data, it’s quite rare to have data imported into a data warehouse in an as-is format. Since raw data is unlikely to be clean and ready to be used, we will need to transform the raw data, which brings us to ELT and ETL.
Extract, Load and Transform (ELT)
In an ELT process, original data from multiple data sources is loaded into a data warehouse immediately without any transformation. Users will then leverage the data warehouse itself to conduct transformation operations to perform basic data quality checks and descriptive statistics. ELT is a good option under the below circumstances.
- All transformation needed to polish the data into a useable format is simple enough to be handled via basic SQL operations.
- Business users prefer immediate access to raw or unconsolidated data to experiment first to check quality or explore the dataset before deciding how transformation needs to be done.
Extract, Transform and Load (ETL)
For an ETL pipeline, data is transformed in the pipeline (a.k.a. in a staging area outside the data warehouse) before being stored in a data warehouse. Each transformation step can be written in Python, Java or scripts or configure via a more intuitive drag-and-drop user interface. ETL is definitely more complex as compared to EL and ELT and should be called upon when dealing with the following challenges.
- The data requires complex transformation such as grouping by, flattening, partitioning, calculations or heavy cleaning steps to solve data quality issues.
- Sensitive information needs to be removed before loading into the data warehouse for compliance or security purposes.
Since complex transformation happens before loading into the data warehouse, the greater the data volume, the longer business users have to wait before accessing the data. That’s probably one of the biggest drawbacks of ETL as compared to ELT.
Change data capture (CDC)
The CDC approach is very different from EL, ELT and ETL. Traditionally, data is often extracted in batches from various sources. In some cases, a database cannot support both enterprise applications (which support the day-to-day business transactions) and the batch extraction to the data warehouse at the same time.
Well, how about only copying databases during non-working hours, or whenever the production will not be heavily impacted? Unfortunately, only updating analytical data during stipulated hours means data will quickly go stale during working hours when fresh insights are needed the most. This is increasingly unacceptable in our always-on world because data will lose its value. So how?
An alternative approach is to capture incremental data changes in a source system into the data warehouse. In other words, instead of replicating every single row in the database, we only load row changes such as inserts, updates, deletes as well as metadata changes into the data warehouse. CDC approach brings about two key benefits.
- Able to capture all changes over time and not just the state of the data sources at the time of data extraction without disrupting business operations
- Enable the most current data to be captured in the data warehouse (or other streaming analytics applications) for faster and near real-time tactical decisions as and when businesses need
If you are interested to know more about CDC approach, check out this article or the book titled “Streaming Change Data Capture” by Dan Potter et. al.
Ten-second takeaway
The method you use to load data into the data warehouse depends on how much transformation is required and whether it’s better to continuously capture incremental data changes than replicating the entire data sources based on fixed schedules.
Wrapping Up
So there it is! Admittedly anything basic might not be particularly excited, especially considering all fancy technologies and advanced techniques to process data. However, through introducing basic concepts of a data warehouse, I want to leave you with a slightly bigger perspective about data processing: Before jumping straight into any advanced analytics and machine learning, we need to gather all relevant data scattering everywhere into a single version of truth, then making it easily accessible, quality-assured, in a usable format and quick to query. Data warehouse might just be a means to an end, but getting it right will decide whether your insights are of any value to the business.
Thank you for reading. If you find this article useful, follow me on LinkedIn and Twitter for exciting stories about data, business and anything in between. Until next time!
