

Knowing how to integrate data from various sources and perform simple transformation to address data quality issues is the first step towards extracting insights from big data. In this blog post, we will explore how to build and deploy simple ETL data pipelines without coding via Cloud Data Fusion on Google Cloud Platform (GCP).
You’ll learn:
- Why do we need Cloud Data Fusion?
- How to build and deploy ETL pipelines with Cloud Data Fusion?
Why do we need Cloud Data Fusion?
The problem: Your first hurdle towards great insights from big data
Despite the rising popularity of sophisticated data analytics and machine learning techniques, something has never changed. The first hurdle towards great insights is usually data integration, which includes gathering relevant data scattering everywhere into a single, unified location and performing a number of pre-processing steps to make it clean and usable.
Our data integration need might be very simple such as removing null values, joining various datasets together, eliminating irrelevant columns or putting all into a data warehouse for quick queries. Yet being a business user with limited technological knowledge, such simple needs might trigger discomfort since you often have to consider two equally inconvenient options.
- You need to learn how to code to do it on your own
- You gotta wait for a while until the data engineering team has the bandwidth to help you out with building a bespoke data pipeline (And let me gently remind you that in reality, not every company has sufficient budget to hire a data engineer, let alone funding a data engineering team.)
How now, brown cow?
The solution: How Cloud Data Fusion can help
Powered by the open source project CDAP, Cloud Data Fusion is a fully managed, cloud-native, enterprise data integration service for quickly building and managing data pipelines. – From Google Cloud
With Cloud Data Fusion available on Google Cloud Platform, you don’t have to know how code to make simple things happen. In short, here is what you can do with Cloud Data Fusion.
- Build data pipelines to gather data from multiple sources and put them into a single location to query and extract insights
- Transform data to address any data quality issue or shape it into a usable format
- Automatically manage all aspects of deploying data pipelines such as provisioning infrastructure, cluster management and job submission
Why does it even matter for you anyway? Well, in layman’s term, here is why it matters.
Without writing any code, you don’t have to be an expert in each and every single data sources to be able to stitch everything together for some quick insights. Spending less time on coding (and making sure that it works all the time) means more time to get to know your data, answer more burning questions about business performance and how you can make better decisions. What’s not to like?
Moreover, since deployment of data pipelines is automated and fully-managed, you don’t have to sweat about IT infrastructure. This means getting the outcome that you want faster without freaking out about managing everything at the back-end. After all, why would any business users want to bother with understanding what infrastructure even means or how to provision an instance or manage a cluster anyway?
How can we use Cloud Data Fusion?
Enough talking, let’s take a look at how to build and deploy a simple ETL pipeline combining 2 different data sources.
Initial setup
Prerequisites
Here is what you need to have before getting started.
- Create a Google Cloud project and enable billing
- Check roles and permissions associated with your account via Navigation Menu > IAM & Admin > IAM. You would need the Admin permission to enable the Cloud Data Fusion API
Create a Cloud Fusion instance
- On the main GCP Console page, type “Cloud Data Fusion” into the Search box.
- Select Cloud Data Fusion API.

- Upon seeing the below screen, select Enable.

- Refresh the page and select the Navigation Menu. Scroll down all the way to BIG DATA and select Data Fusion.
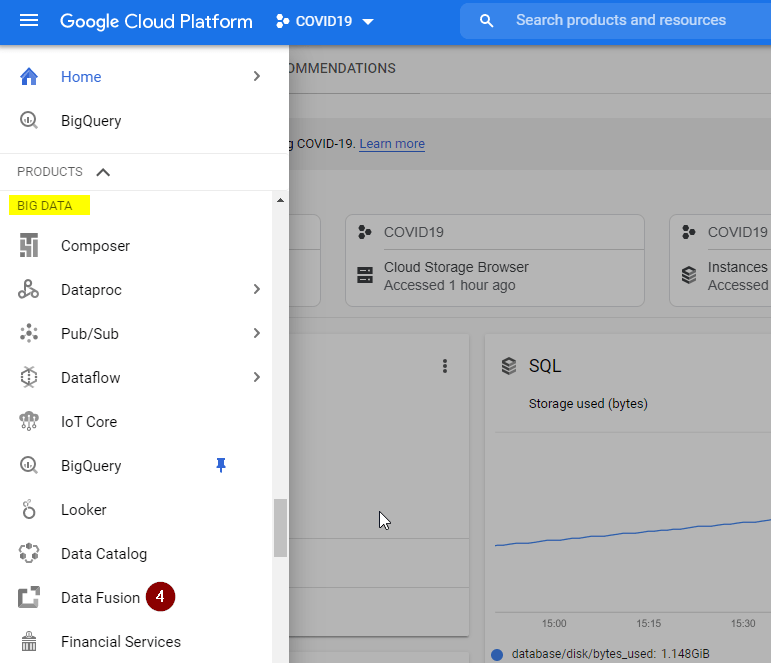
- Click Create an Instance.
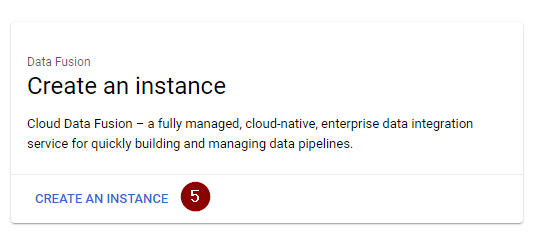
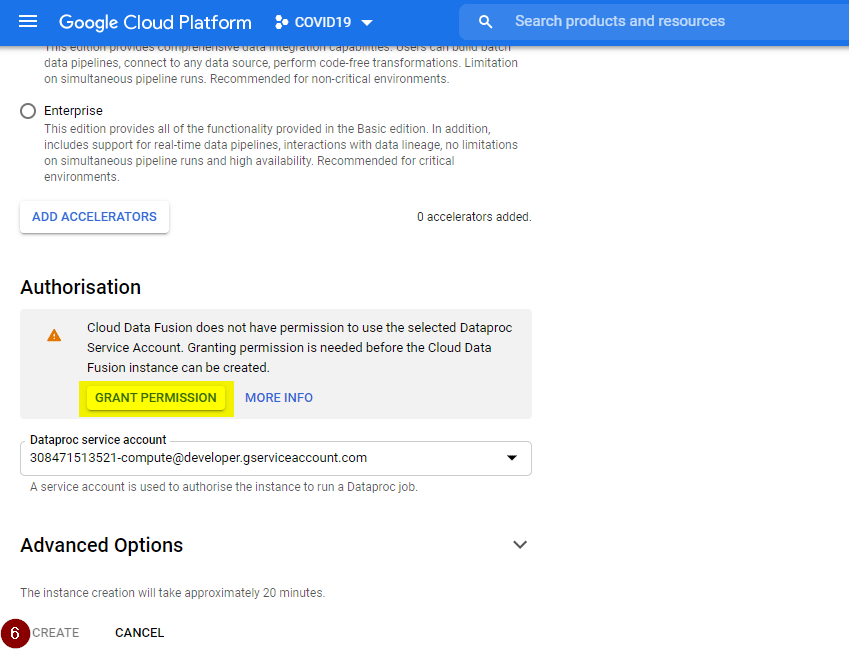
- Follow the instruction on the screen to enter a name for your instance. Select Basic for the Edition type and leave all other fields as their defaults. Click Create. But if you see the Create button is greyed out (like the screenshot below), make sure to click Grant Permission first.
- Upon clicking Create, the instance creation process might take about 15-20 minutes. Once creation is completed, you will receive a Notification where the bell button is.
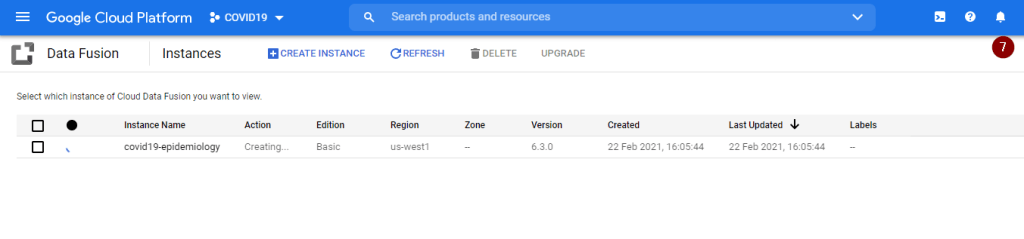
- Once the instance is created, let’s grant the service account associated with the new Data Fusion instance permissions on your project. To proceed, click the instance name (not the View Instance) and copy the Service Account to your clipboard.
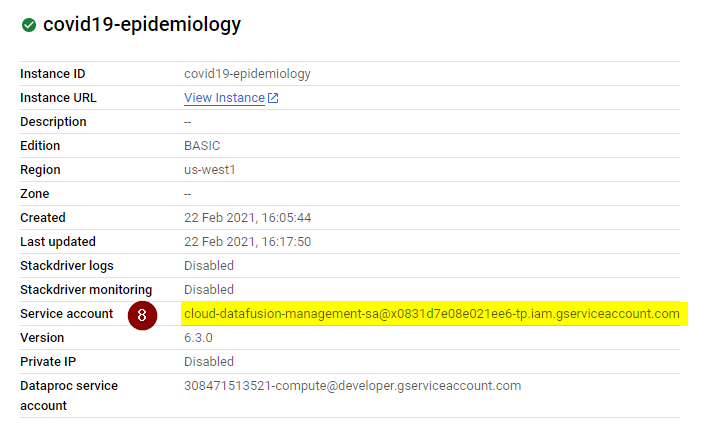
- Go to Navigation Menu > IAM & Admin > IAM, click Add.
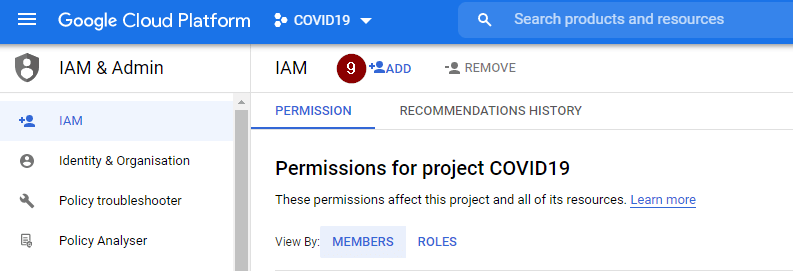
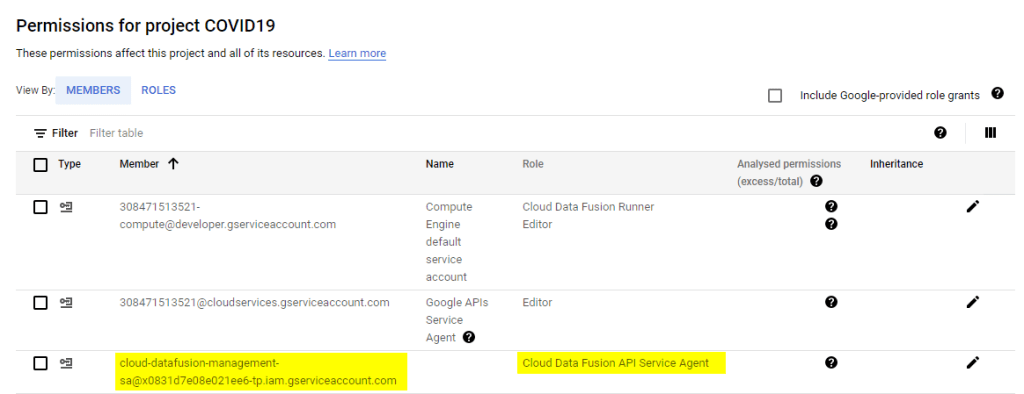
- Add the copied service account as a new member. Click Select a role and type Cloud Data Fusion into the filter box. Among all filtered options, select Cloud Data Fusion API Service Agent role. Then click Save.

- Before proceeding any further please ensure that the service account associated with the newly created Data Fusion instance is visible as one of the granted permissions for your project (similar to the picture below).
Create an ETL data pipeline
The plan
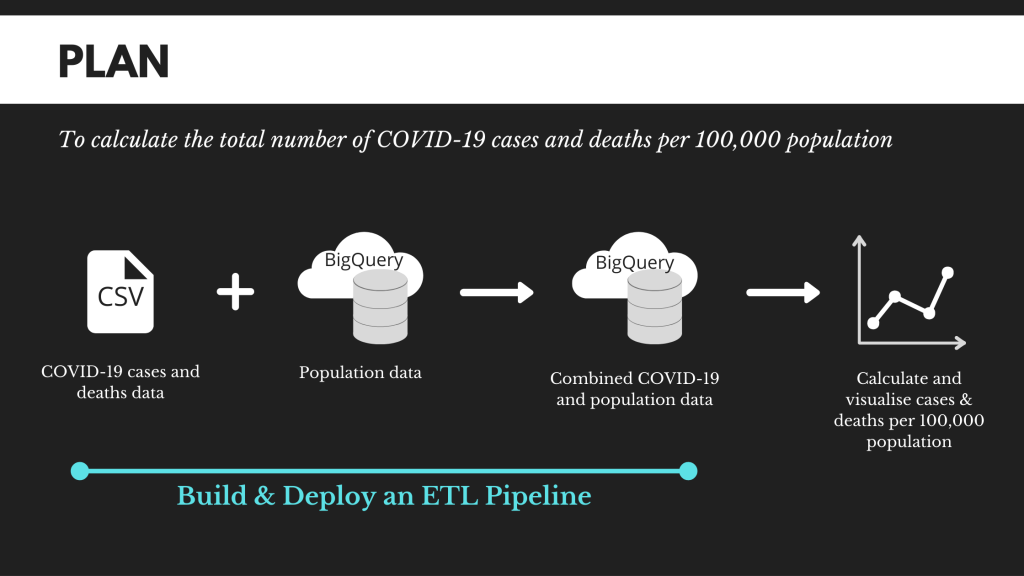
To compare and contrast the severity of COVID19 spread across different countries, we often can look at the total number of cases and deaths. However, representing the number of cases and deaths as it is simply won’t work because each country has vastly different population size.
Taking into account different population sizes, a much more common approach is to compare the total number of cases and deaths per 100,000 populations.
Total number of cases per 100,000 populations = Total number of cases / Population * 100,000
Unfortunately, information about number of cases and deaths doesn’t include population data. Therefore, we will build an ETL pipeline to combine a CSV file file (having the total number of cases and deaths) with a BigQuery table (containing population per country) using Cloud Data Fusion.
The dataset used for this blog post is extracted from the COVID-19 public dataset, which is available on Google Cloud Platform or this GitHub. Before we get pipelining, below is our plan.
Load CSV data
- From the Navigation Menu, go to Data Fusion and click View Instance.
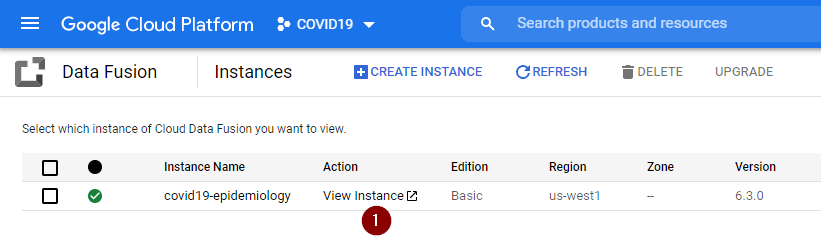
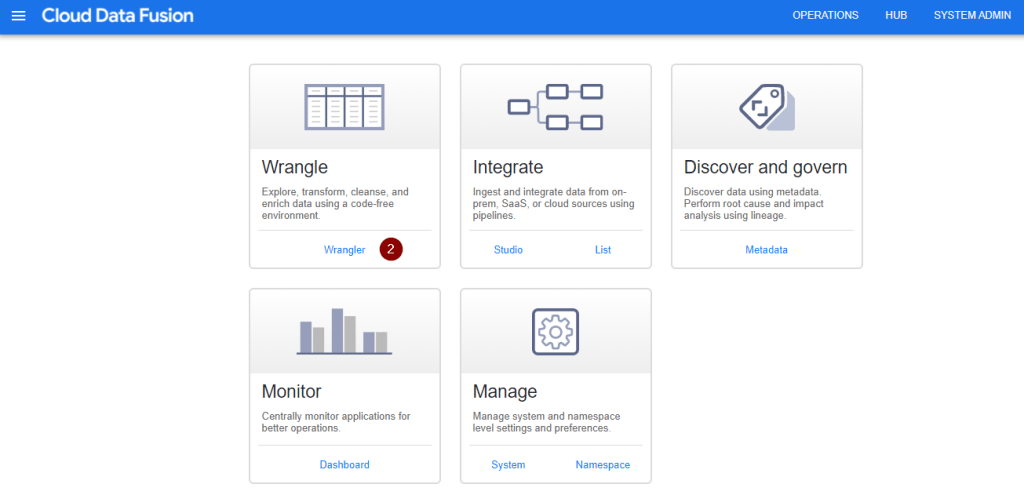
- Follow the prompt on the screen and you should be able to see the Cloud Data Fusion UI as shown below. As I personally want to start with some data exploration, click Wrangler. If you want to explore other options, feel free to experiment with the UI.
- Let’s load the CSV dataset into the pipeline by selecting the Cloud Storage Default on the left side, and clicking on the name of the bucket containing the number of cases and deaths per country over time.
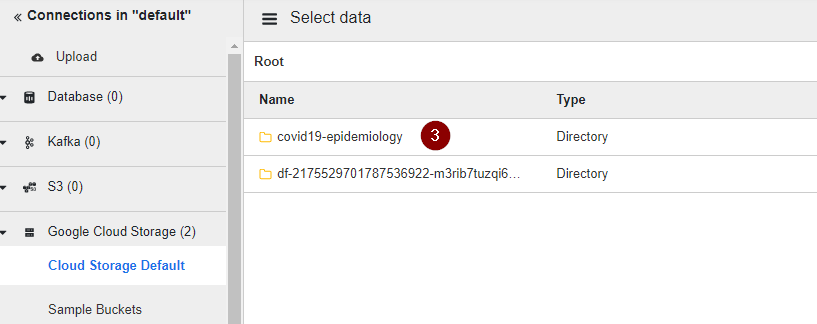
- Select the table name.
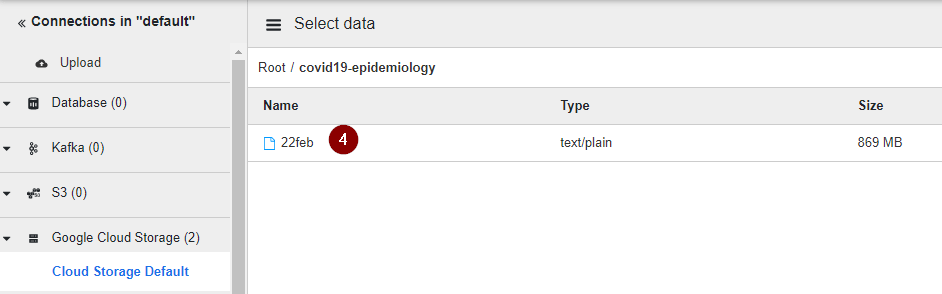
- Once the data from CSV is loaded, you may notice that all attributes are combined under the same body column. So we will have to parse the CSV data into proper columns. Click the Down arrow located on the left of the body column and select Parse > CSV.
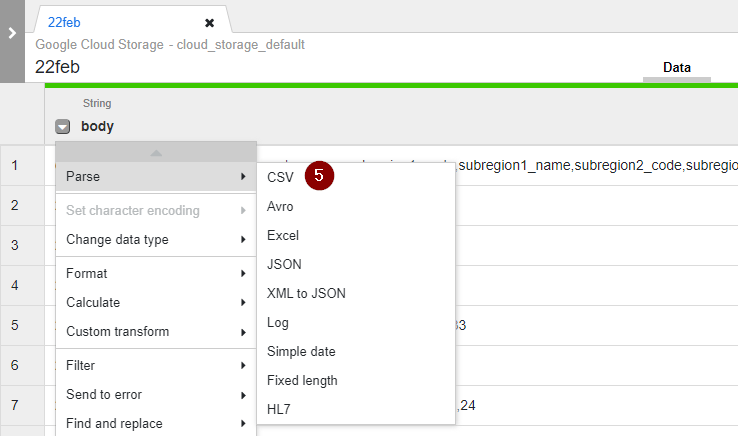
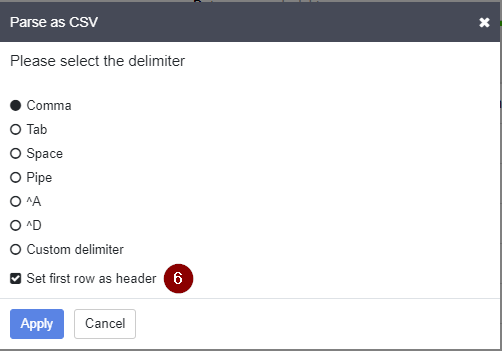
- Select the appropriate delimiter and tick the box for Select first row as header. Then click Apply.
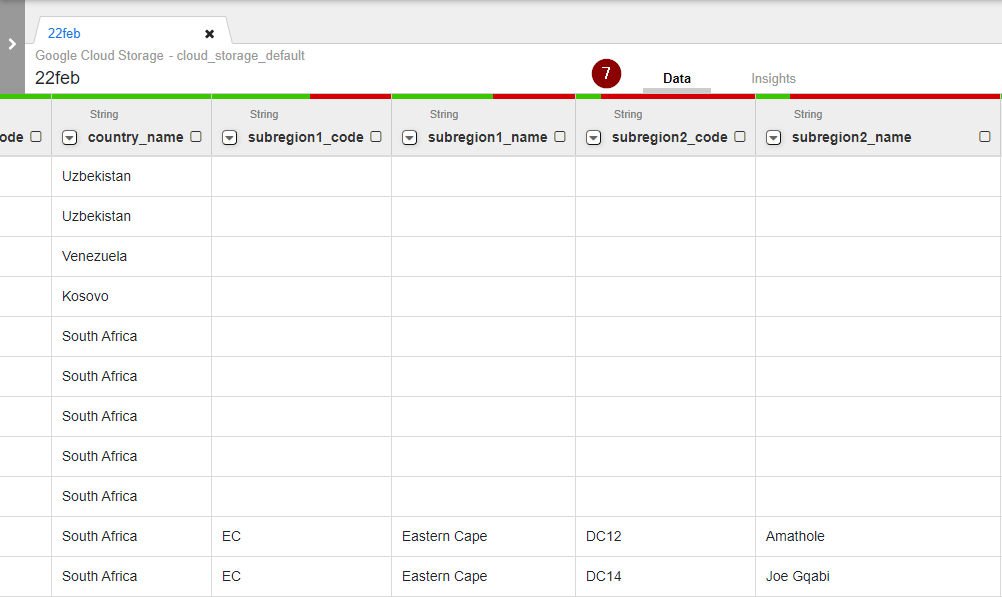
- As different attributes are split into their respective columns, we may now start exploring our dataset. Take a look at the screenshot below. Can you guess why some columns such as country_name are all green while subregion2_code shows a bit of green and the majority is red?
TIP: The red colour represents the proportion of null values for each column. Simply put, if majority of the bar is red, you can easily note that data attribute might not be so useful for analysis due to many missing values.
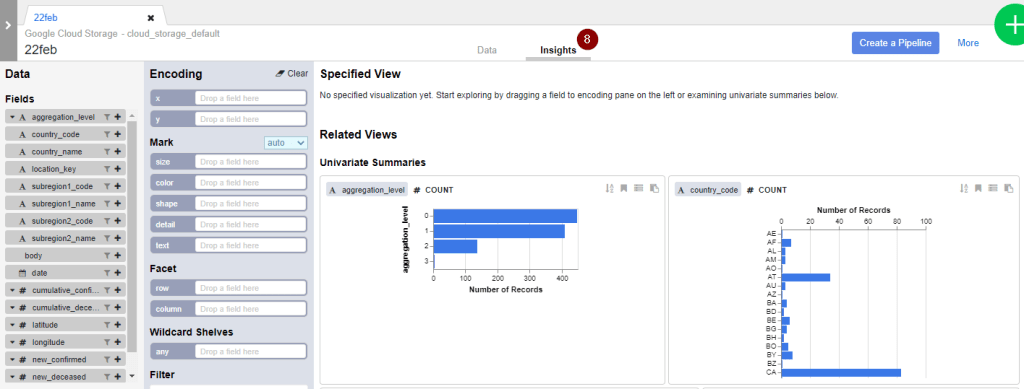
- Another useful feature to explore the data in a more visual way is with Insights. For example, here I can easily observe that this data set contains different levels of aggregations from 0 to 3. This is something I have to handle with care since I am only interested in country-level figures instead of subregion-level figures.
TIP: Be careful with jumping into any conclusion because the insights are generated from 1,000 samples from the dataset. This might be good for some initial understanding but it does not represent everything available in the entire dataset.
Transform CSV data
After examining the CSV data in details, below are a few common data transformation steps we can do to clean and shape raw data into a usable format.
Filter rows by specific values
As mentioned above, the dataset includes number of COVID-19 cases and deaths per country (which is what we want) as well as those figures per subregion (which is what we don’t want).
To retain only country-level figures, click the Down arrow next to the aggregation_level column and filter to keep rows with aggregation_level = 0
Remove redundant columns
At the menu to the right, tick the box(es) to select the Columns that you want to retain. Then click the Down arrow next to any of the selected column and click Keep selected column.
Once the redundant columns are removed, click on the Down arrow next to # and select Clear All to go back to the normal Data view for subsequent transformation steps.
Convert string to numerical data types
For each numerical column (e.g. new_confirmed, new_deceased, cumulative_confirmed, cumulative_deceased), click the Down arrow, select Change data type and choose Integer for whole number or Float for decimal values.
Parse string to date
To convert string to proper date type, for each date column, click the Down arrow, select Parse > Simple date.
Select the appropriate date format and click Apply.
Change column name
To change the original column name into a more intuitive one (for example from cumulative_confirmed to total_case), double-click on the column header, type the new name and press Enter.
Once you are happy with the final format of the CSV data, click Create a pipeline and then select Batch pipeline.
But remember we also need our population data, which is currently located inside a Google BigQuery table. So let’s bring it in.
Load the BigQuery table containing population data
- From the menu on the left, navigate to Source and select a data source that you are trying to integrate. Here I am selecting BigQuery.
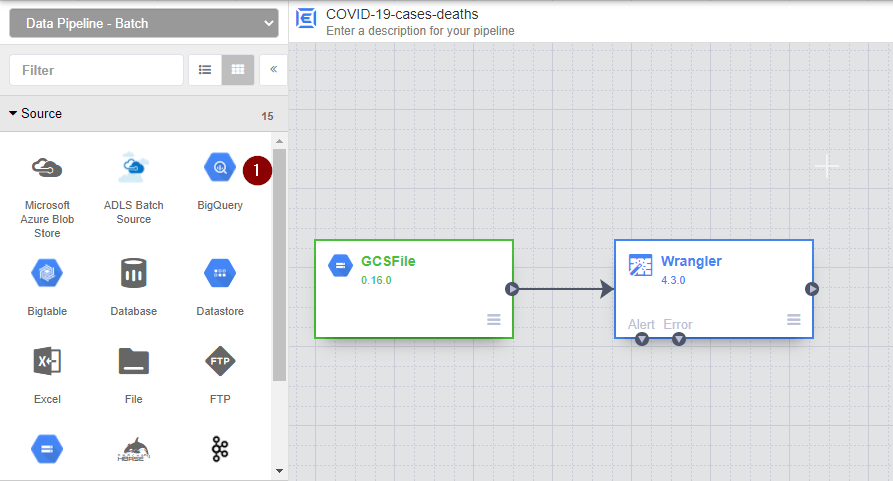
- Once the new node for BigQuery source appears, hover over the BigQuery node and click Properties.
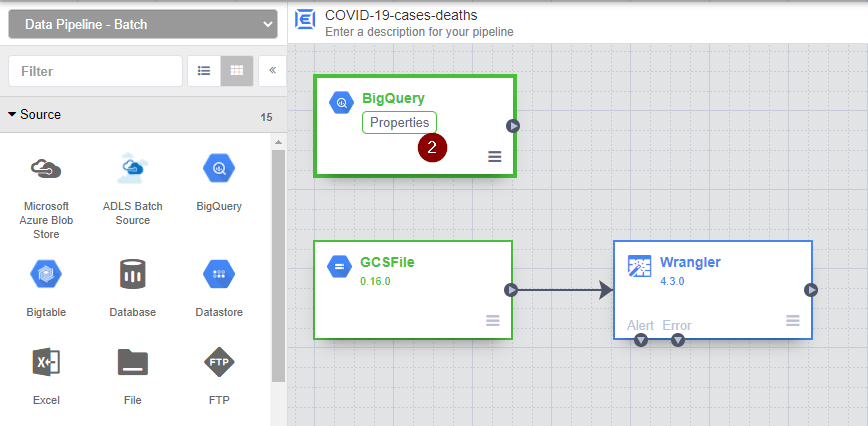
- Select Browse.

- Navigate to the Google BigQuery table that you want to integrate
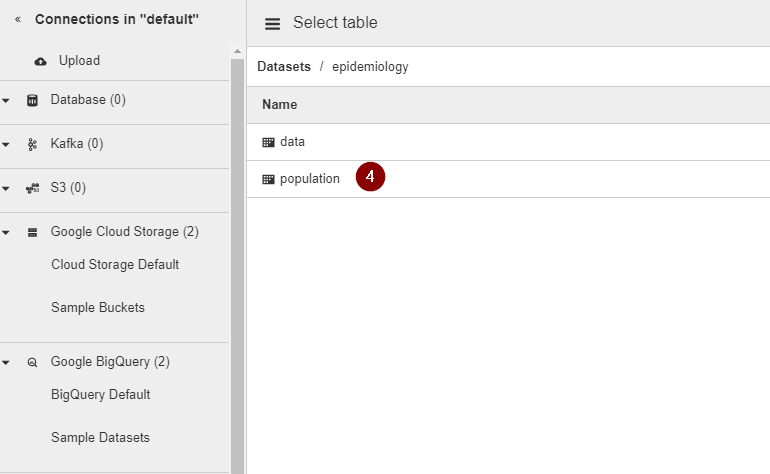
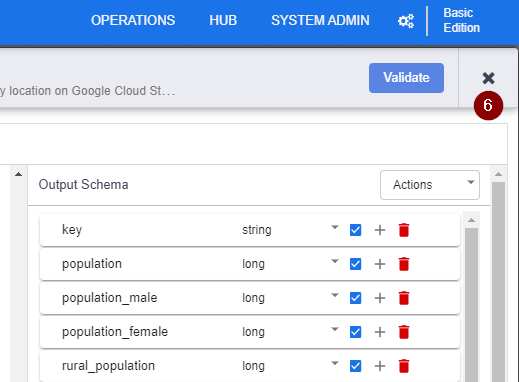
- To validate whether the BigQuery table contains the correct information that you are looking for, click Get Schema. All columns of the BigQuery table will appear on the right side of the wizard for your review.
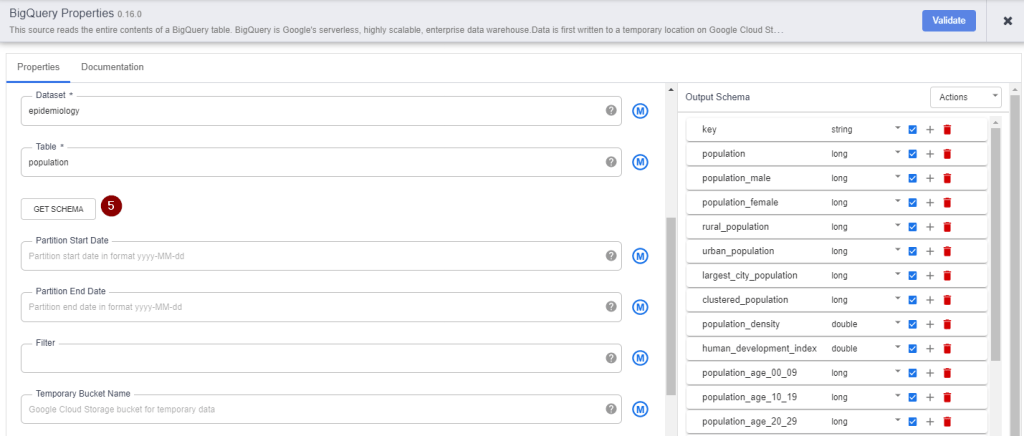
As you can see from the schema, we don’t need every single column of the BigQuery table. So let’s eliminate what we don’t need. But first, we will need to exit the BigQuery properties.
- Click the X button in the top right corner to exit the BigQuery properties and go back to the data pipeline.
Transform BigQuery data
- To eliminate redundant column, we will need to use the Wrangler. On the left menu, navigate to Transform and select Wrangler.
- To connect 2 nodes together, drag the connection arrow on the right edge of the BigQuery node and drop on the new Wrangler node. Hover over the new Wrangler node and click Properties.
- To avoid getting confused with the previous Wrangler node that we use to transform CSV data, let’s give this node a new name by specifying a new Label. Click Wrangle to configure the steps to clean and shape the data.
- Navigate and select the BigQuery table containing the population data that we need to clean.
- With this population dataset, we only need the “key” and “population” column. Therefore, similar to how we eliminate redundant columns for the CSV file, at the menu to the right, tick the box(es) to select the Columns that you want to retain. Then click the Down arrow next to any of the selected column and click Keep selected column.
- Click Apply to go back to the Properties view. Then click the X button in the top right corner to exit the BigQuery properties and go back to the data pipeline.
Join 2 data sources together
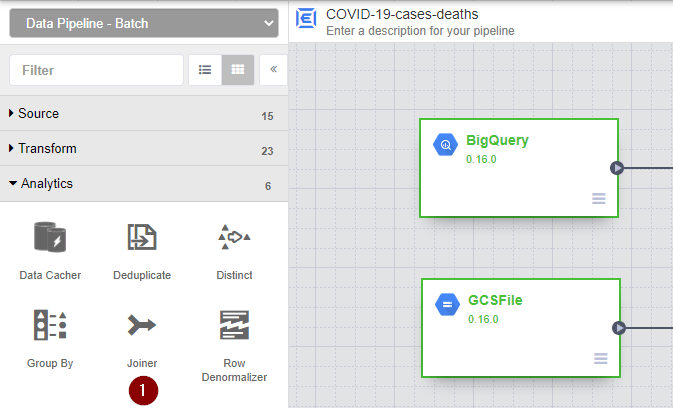
It’s time to join the COVID-19 data and the population data together. This time, we will need to use the Joiner node, which locates under the Analytics section.
- From the menu on the left, navigate to Analytics and select Joiner.
- Once the new Joiner node appears on the screen, connect the two Wrangler nodes to the Joiner node by drag and drop the connection arrow. Then hover over the Joiner node and click Properties to configure how the 2 tables should be joined together.
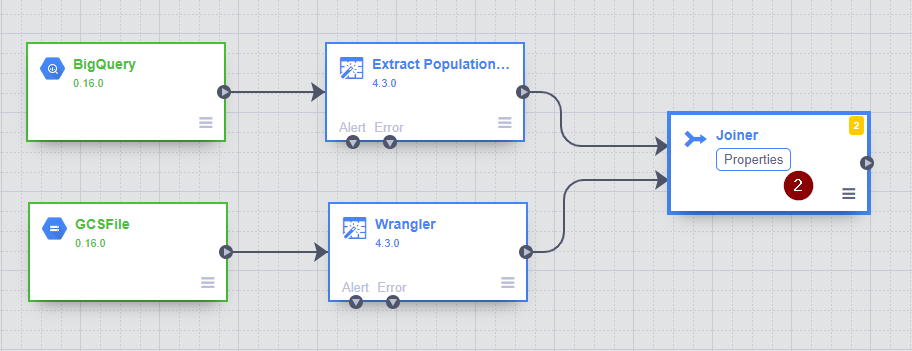
- Specify the Join Type and Join Condition. Here we are doing an inner join to match the “key” column from population dataset and the “location_key” from the COVID-19 dataset. Click Get Schema to validate whether the output columns are what you are looking for.

- Once you are happy with the output, click the X button in the top right corner to exit the Joiner properties and go back to the data pipeline.
Store the final dataset in Google BigQuery
As we have successfully stitched the COVID-19 data and the population data together, final step to our ETL pipeline is loading everything into a storage place (i.e. a sink) so that you can always go back and analyse the data.
Here I am choosing to store the final dataset ino Google BigQuery because I can easily query it with SQL to calculate cases and deaths per 100,000 countries or connect it with any data visualisation tools such as Tableau, Google Data Studio and so on.
- From the menu on the left, navigate to Sink and select BigQuery.
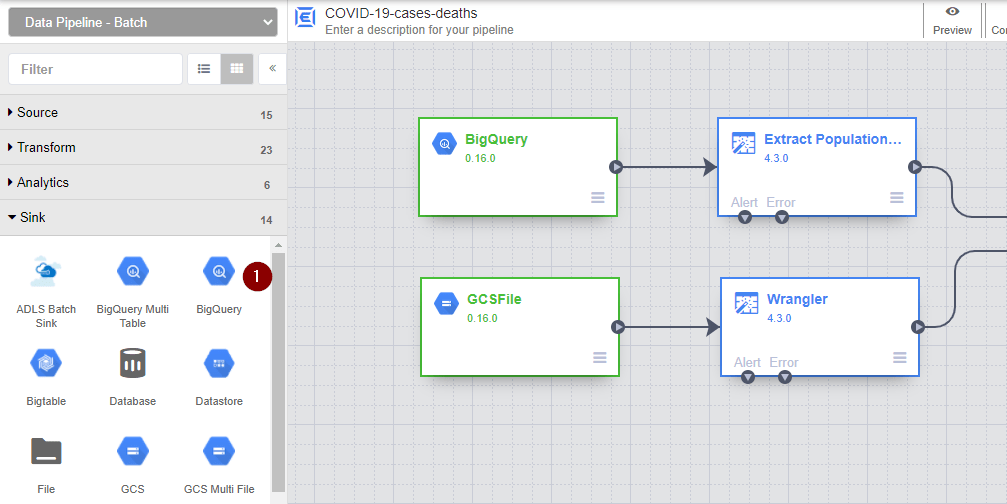
- Connect the Joiner node to the newly created BigQuery node. Hover over the BigQuery node and click Properties to configure the data storage.
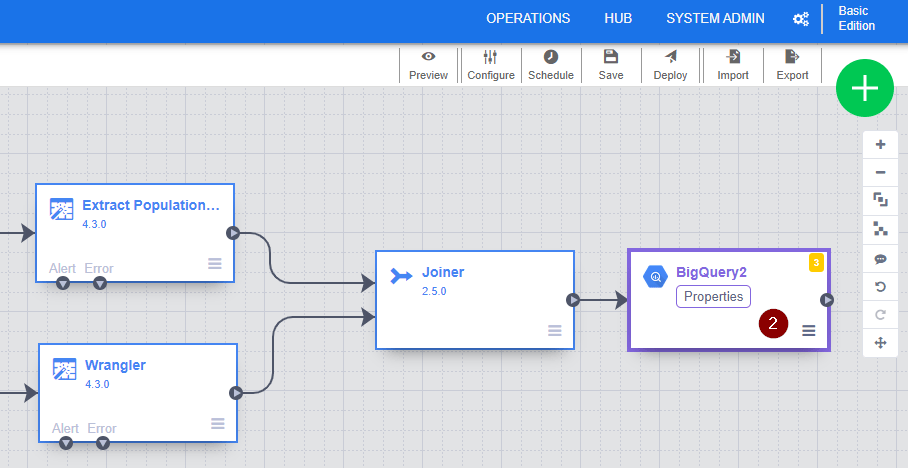
- Specify the Reference Name, Project ID, Dataset and Table that you want to store the combined dataset.

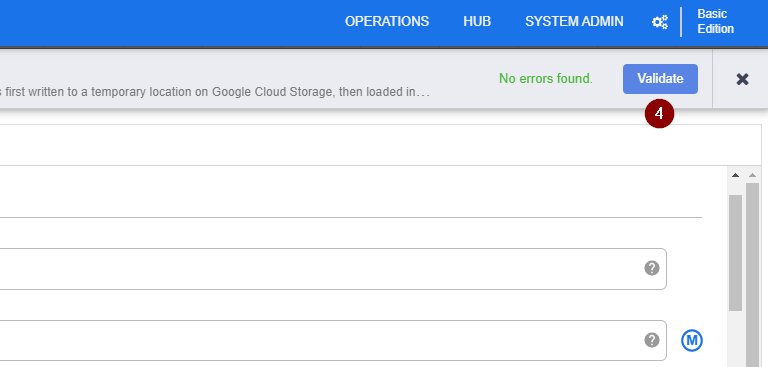
- To ensure all things are specified correctly, click Validate. Once you see that No errors found, click the X button in the top right corner to exit the BigQuery properties and go back to the data pipeline.
Review the ETL data pipeline
Finally, we have completed building our very first ETL data pipeline to combine COVID-19 data and population data to calculate number of cases and deaths per 100,000 populations. Here is what our simple ETL data pipeline looks like at the moment. Drum roll everybody!
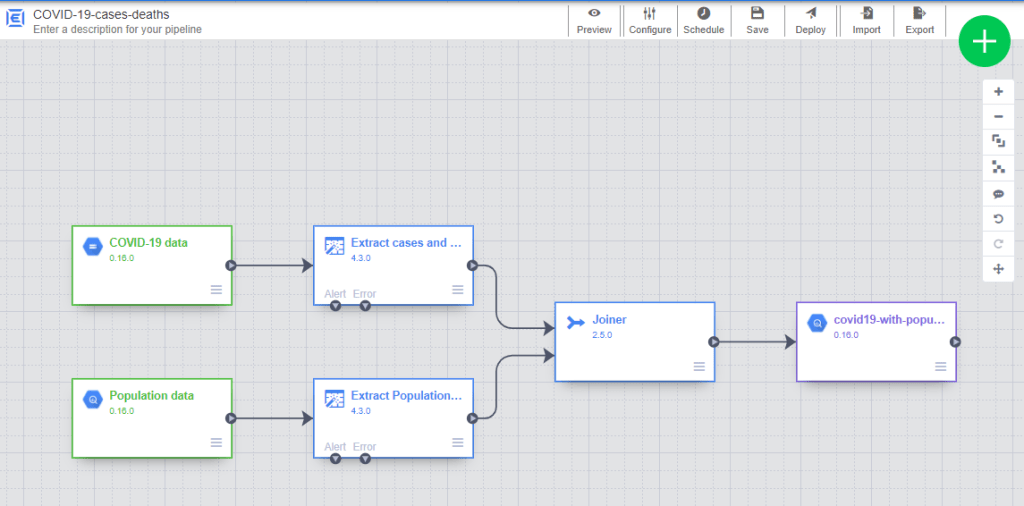
Before jumping straight into deployment, I would highly recommend to spend 15-20 minutes to review the ETL pipeline from start to end as well as name your pipeline.
TIP: Don’t forget to give each node a meaningful name. The last thing you want is 3 months down the road, you find yourself staring at 5 different Wrangler nodes and scratching your head while trying to understand what’s the difference between Wranger3 and Wranger5. Let’s be kind to yourself and to whoever might inherit this ETL pipeline, shall we?
Deploy an ETL pipeline
Okay! It’s time to see our ETL pipeline in action. Are you ready?
- In the upper-right corner of the page, click Deploy.

- Upon seeing the below screen, click Run to initiate the data integration process immediately. Alternatively, you can click Schedule to set up daily or weekly execution of this ETL data pipeline or monitor Status. Do note that it will take a while to complete and the status would become Succeeded.
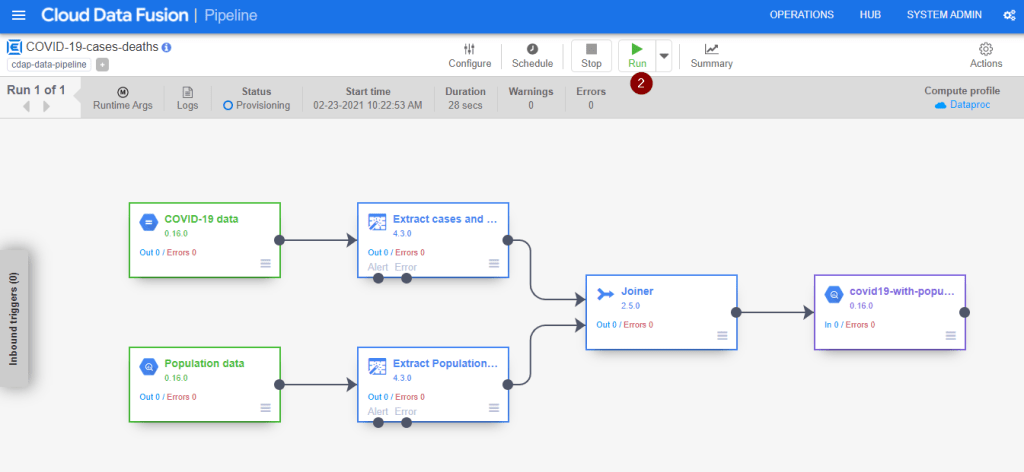
Calculate the total number of cases and deaths per 100,000 populations in BigQuery
Once the ETL pipeline run has completed, below is the combined dataset you can expect to see in BigQuery.
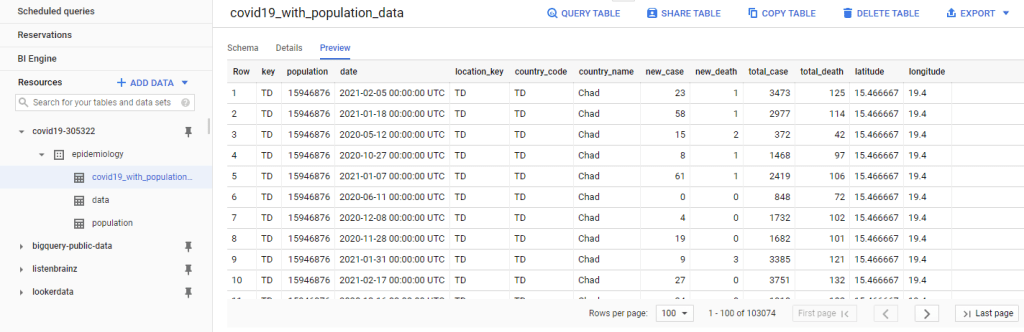
Since COVID-19 data and population data is now nicely stitched together in one place, writing a SQL query to calculate total number of cases and deaths per 100,000 populations over time can’t be any simpler.
SELECT
EXTRACT(DATE
FROM
date) AS record_date,
country_name,
new_case/ population*100000 AS new_case_per_100k_pop,
new_death/ population*100000 AS new_death_per_100k_pop,
total_case/ population*100000 AS total_case_per_100k_pop,
total_death/ population*100000 AS total_death_per_100k_pop
FROM
`covid19-305322.epidemiology.covid19_with_population_data`;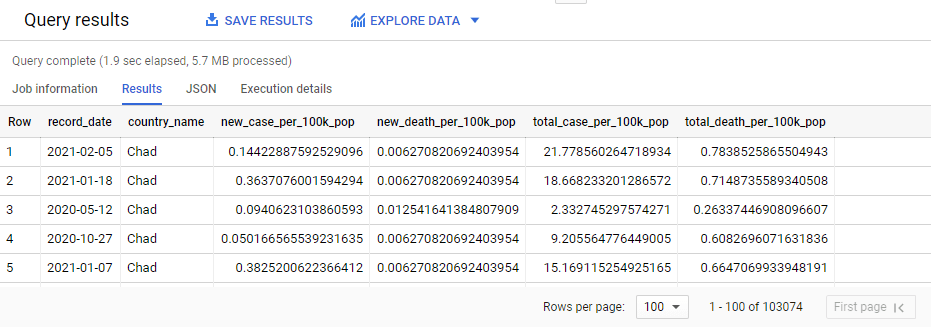
Wrapping Up
Let’s face it! Spending less time on coding and managing infrastructure means more time to get to know your data, answer more burning questions about business performance and how you can make better decisions. And Cloud Data Fusion is just one among many other data integration solutions in the market that help business users get good data scattered everywhere into a single location without having to worry about the complexities of coding or managing infrastructure. The time is now to empower business users with the tools and capabilities to translate big data to business insights quickly while keeping simple things simple.
Thank you for your time and if you find this article useful, follow me on LinkedIn and Twitter for exciting stories about data, business and anything in between. See you in the next one!
