

In the emerging world of 2021, big data and machine learning are still the holy grail while the need for superior speed and agility continues to accelerate cloud adoption. Does the old Hadoop technology even have a place in this new world? To shed some light on that question, let’s reflect on what Hadoop is and how the cloud is impacting Hadoop.
In this article, you’ll:
- Get to know Hadoop
- Explore Hadoop on the cloud
- Look to the future and beyond with modern cloud platforms
Get to know Hadoop
Why was Hadoop a big deal?
Once upon a time, as our business grew, we started to generate too much data to be stored and processed with a single computer.
Maybe it’s time for an upgrade? Alright, so we bought a better computer, much more advanced and of course much more expensive than the previous one.
Until one day, again, we generated too much data that this new computer also gave up. Yet buying one after another advanced computer was simply too expensive to afford.
If there were too much data to store on a single computer, how about splitting it up into smaller chunks and store them across multiple computers?
If it took too long to process all data with a single computer, why don’t we split the processing job into smaller jobs and let multiple computers process those chunks in parallel?
As you might have guessed, Hadoop made those two ideas a reality.
No more spending a fortune to go after the most advanced computer in the market! Businesses can buy more everyday affordable computers to keep up with the ever-growing need to store and process more data. Therefore, at its core, Hadoop provides a reliable, scalable and cost-effective platform to store and process petabytes of data by distributing a very large workload across many individual computers.
What does the Hadoop ecosystem look like?
Core components of Hadoop
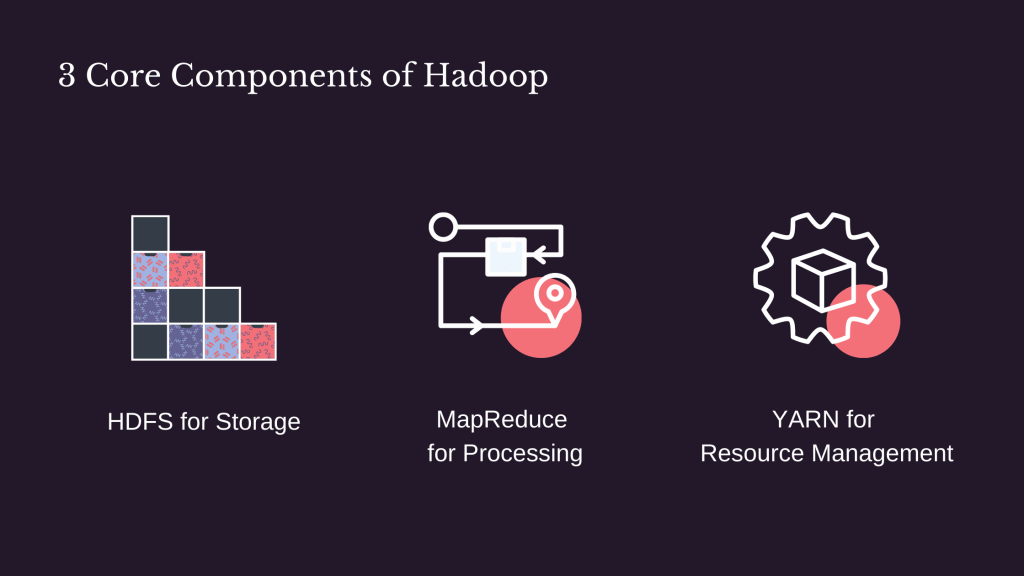
Being the storage layer, HDFS is where the data, interim results and final results of all data processing tasks are captured. Upon storing a file in HDFS, the system breaks it into evenly sized blocks of data and store these blocks in many individual computers (a.k.a. the Hadoop cluster).
If HDFS is all about breaking big data into manageable blocks for storage, then MapReduce is all about divide a big problem into many bite-size pieces so that you can process them in parallel and solving the problem faster. The Map task processes the block of data individually on the computer where it’s stored while the Reduce task combines all results obtained from individual computers into a single result set.
MapReduce handles data processing while YARN is meant for resource management, ensuring each and every job is allocated to suitable computers for completion. . This enables Hadoop to run different workloads other than MapReduce, ultimately expanding Hadoop capabilities to support other applications to process streaming data or running ad-hoc data analysis.
Other bits and pieces of the Hadoop ecosystem
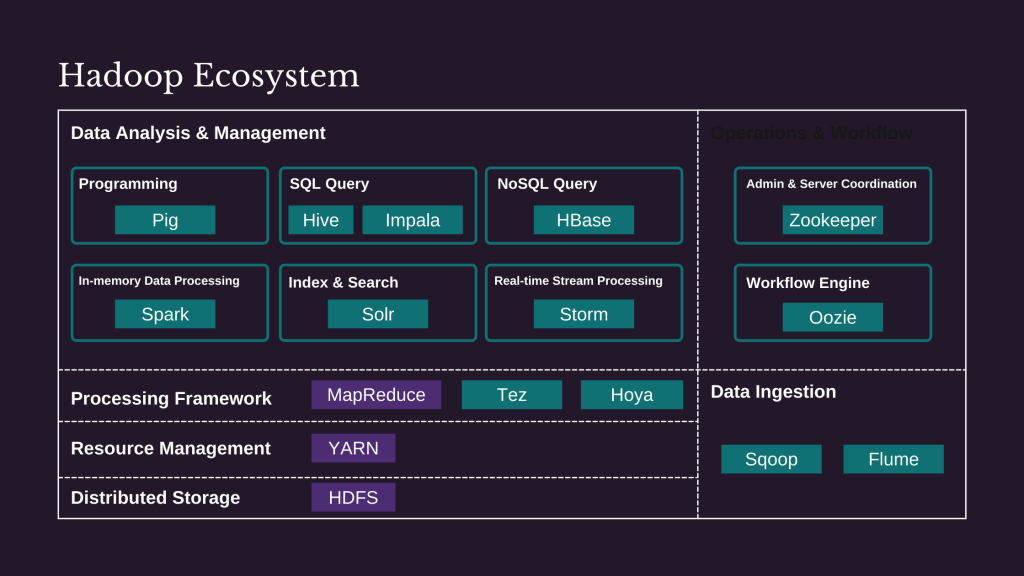
With its 3 core components, Hadoop is just a general-purpose platform to store and process data without any special capabilities to search or query structured data. This means it needs other components to form a complete solution for analysing big data.
For example, we need Sqoop and Flume to collect structured data in batches (from relational databases or data warehouses) and event data in stream (from IoT devices or social media networks) respectively into HDFS for analysis and insights.
Also, we require additional tools to cater to different tasks such as programming with Pig, query structured data with Hive or index and search with Solr. Besides, other workflow management tools such as Oozie also plays a crucial part in scheduling and managing Hadoop jobs.
In short, it is the larger ecosystem of open source components that make Hadoop useful in answering business questions.
Ten-second takeaway
At its core, Hadoop provides a reliable, scalable and cost-effective platform to store and process petabytes of data by distributing a very large workload across many individual computers. You can buy how many computers you need, install the components you want, leave what you don’t, and add your nuances depending on your business requirements.
Explore Hadoop on the cloud
How does the cloud fit into the Hadoop picture?
So far, we only discussed on-premise Hadoop where companies buy, build and maintain many computers to store and process big data. But technology has immensely changed since then.
What if you can run Hadoop in the cloud? In other words, you simply rent how many computers you need from cloud providers such as AWS, Google Cloud Platform or Microsoft Azure to install Hadoop and process data for how long (or how short) you want, while paying them like a monthly electricity bill.
Before we explore why anyone would like to move Hadoop from on-premise to the cloud, it’s important to understand what the cloud means. Here is a simple definition extracted from my favourite book “Explain the Cloud Like I’m 10” by Todd Hoff.
The cloud is a network of computers, accessed over the internet that provides some sort of service. You don’t care where those computers are located or how they work. You never see them. You never touch them. They are just a cloud of networked computers for you to use.
Todd Hoff
Why should we even consider running Hadoop on the Cloud?
The idea of running Hadoop on the Cloud turned out to encompass many compelling advantages. Below are two key problems that moving Hadoop to the cloud could nicely address.

It would be incomplete without mentioning the below 2 important points regarding running Hadoop on the cloud.
- Many companies can’t or aren’t comfortable with the idea of completely abandoning the expensive longstanding on-premise infrastructure. Therefore, they could opt for a hybrid cloud architecture to run certain jobs on-premise (if the data simply can’t be put up into the cloud for security reasons) and handle other workloads on the cloud. Life would be more complicated that way but could be good enough in special circumstances.
- Running Hadoop on the cloud isn’t the silver bullet to all problems. For example, there is no guarantee to save more money. You still need to pay for what you have requested, regardless of whether you use it or not. Installing Hadoop components, fine-tuning performance and handling the networks properly still takes time and requires serious expertise.
Ten-second takeaway
Since running Hadoop on the cloud simply means business as usual, but in the cloud, it’s far from a perfect solution to process big data for analysis and insights. However, it does offer some glimpse of hope as the cloud can save you a lot of work while getting your Hadoop up and running much quicker.
Looking to the future and beyond with modern cloud platforms
As we descend more deeply into the new world of cloud, I personally don’t see the point of running Hadoop on the cloud. Why should we settle for less when we also have a whole spectrum of choices to store and analyse big data via modern cloud platforms?
But first, we need to know what the choices are. So let’s find out!
Option 1: Managed Hadoop services
Being is a step up from running Hadoop on the cloud, the first choice means leveraging prepackaged Hadoop services provided by cloud providers. Some examples include AWS Elastic MapReduce (EMR), Google Cloud Dataproc and Microsoft Azure HDInsight.
Here is how it works: You create Hadoop clusters on-demand, define what MapReduce or Spark jobs are needed, let them execute those data processing tasks and turn them off upon getting the result. While you still have to pay for the compute resources consumed, you don’t have to worry about how to manually install and configure Hadoop components as well as managing their performance.
Nevertheless, many organisations are skeptical because such prepackaged services might not be enough to cope with complex requirements or lead to vendor lock-in. Moreover, people who have never used Hadoop before are also bypassing it completely to avoid the complexity and high learning curve.
Option 2: Cloud Big Data Solutions
As you might have guessed, big data solutions offered by cloud providers could be the real deal for those who have never used Hadoop before and most probably can’t afford the expertise. Simply put, let’s get rid of Hadoop for good.
At every stage along the data lifecycle (i.e. ingest, store, process and analyse, explore and visualise), major cloud providers such as Amazon, Google and Microsoft offer multiple solutions specifically tailored to end users’ varying big data needs. Just take a look at their product offerings, we can easily see the options are truly endless and equally versatile as compared to what the Hadoop ecosystem brings. What’s more? The intuitive graphical user interface of most cloud solutions means users can get insights from data much faster without having to first become a technical expert in everything.
Another crucial selling point for cloud solutions is the additional component of artificial intellignece (AI) and machine learning (ML). The options can vary from ready-for-use pre-trained ML models to managed AI platform (for building your own models from scratch). The power to inform data-driven decisions with accurate predictions is something that Hadoop could barely match.
Of course, with everything in life, there are always potential trade-offs. In this case, if you are replacing Hadoop with something else, a certain learning curve is unavoidable. Besides, the more engaged you are with vendor-specific solutions, the further you are moving away from the open-source world and the power to work however you like.
Ten-second takeaway
On one hand, getting rid of Hadoop implies moving away from open source solution but offers convenience, ease of use and greater AI/ML capabilities. On the other hand, opting for a managed Hadoop platform calls for dedicated knowledge about Hadoop tools while retaining the freedom of working with whatever open source tools you desire. Unfortunately, there is no perfect one-size-fits-all solution as it’s a matter of choices and priorities.
Parting Thoughts
Does the old Hadoop technology for big data even have a place in this new world of big data and machine learning? I would say at least for now, Hadoop isn’t going away completely any time soon. But we are pretty much in a transition stage with different organisations exhibit varying degrees of letting the cloud either complement or replace Hadoop. Due to the importance of speed and agility, cloud adoption is no longer a question of “if” but a matter of “how soon” and “to what extent”. In a post-COVID-19 future where businesses must be prepared to respond and adapt rapidly, cloud data solutions are here to flourish and could be the vital ingredient to accelerate innovation at scale and unlock additional business value.
If you’re reading this, thank you for your time and I really hope you got some value from this post. Feel free to get in touch or follow me on LinkedIn and Twitter for exciting stories about data, business and anything in between. Long live and prosper, everybody!
