

Expect rain. Only two simple words, yet the stakes sometimes could be much higher than grabbing an umbrella before leaving the house tomorrow. Rain could ruin picnic plans or bring tremendous joy to farmers who are desperate to save their drought-stricken crops.
Learning how to predict next-day rain is a simple and practical way to explore Machine Learning with Google BigQuery. So let’s find out how we can make it happen.
In this article, you’ll discover:
- Why BigQuery ML for Machine Learning?
- How to ingest and split the dataset into a training set and a test set?
- How to train and evaluate a classification model?
- How to predict next-day rain?
Why BigQuery ML for Machine Learning?
Imagine being a data analyst who lives and breathes SQL, you understand the ins and outs of what data resides in the BigQuery data warehouse. You may recently learn some foundational knowledge about machine learning but by no means an avid ML expert who can write Python codes with your eyes closed.
Yet you want to build a Machine Learning model with BigQuery datasets to predict certain behaviours that could be valuable to your business. And you need it quick because, in the business world, time waits for no one.
How are you supposed to make it happen within a short amount of time if you don’t know much about complicated ML frameworks such as Tensorflow or Keras? How are you supposed to write an entire ML solution without going crazy with Python or Java programming?
And that’s where BigQuery ML could really shine. In short, it allows you to create and train Machine Learning models in BigQuery using standard SQL queries. This approach offers 3 key benefits.
- You don’t need to spend a ridiculous amount of time trying to figure out how to export data from your BigQuery data warehouse with a myriad of new tools
- You don’t have to seek heaps of approvals if there are legal restrictions or compliance requirements that strictly govern how exporting data and moving it around for analysis and machine learning should happen (But of course, compliance with access control policies and common sense still applies here.)
- You don’t need to drive yourself nuts to create an ML solution using Python/ Java or join the long waitlist for a chance to trouble someone else (or even an entire team) to help you out.
So what does it mean for the business anyway? This means a simpler and faster way to leverage Machine Learning to predict what might happen in the future and how the business should respond to effectively seize the opportunities or mitigate the risks.
Just a word of caution, currently BigQuery ML on supports a selected range of models. They include linear regression, logistic regression, K-means clustering, TensorFlow, matrix factorization, XGBoost, Deep Neural Network and ARIMA-based time series model.
I personally find the available options sufficient to quickly build a baseline model for common ML use cases . But do check out the BigQuery documentation for the latest list of offerings.
Before we start
Before jumping into BigQuery, here is what we want to achieve: Given today’s observations about Wind Direction, Rainfall, Minimum Temperature, Maximum Temperature, Cloud Cover and so on, can we predict whether it will rain tomorrow?
What we have is a Kaggle dataset containing 10-year weather observations across selected locations in Australia between 2007 and 2017. Below is our game plan on how to translate the dataset into a classification model that we can use to predict next-day rain in 2021.
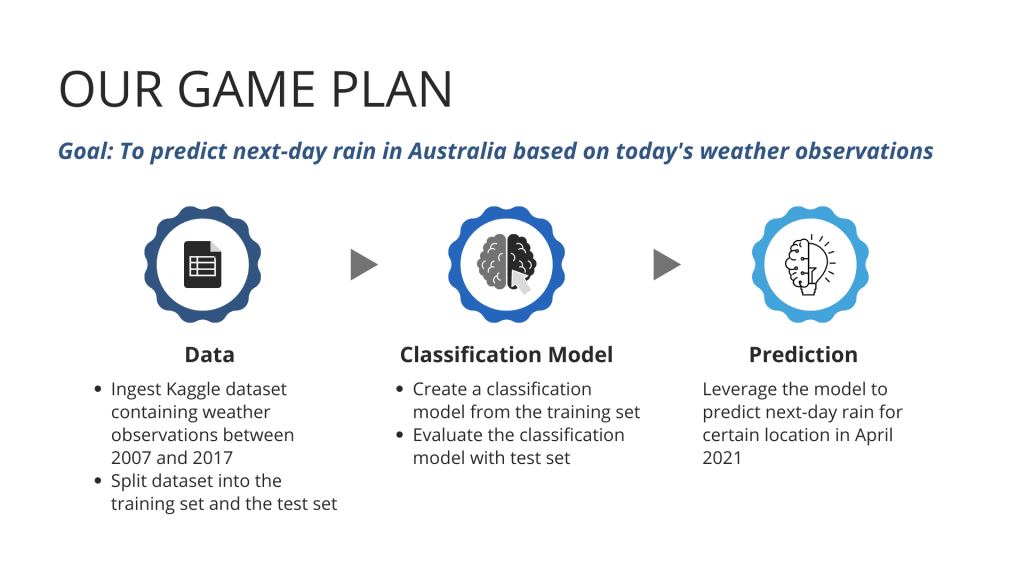
Admittedly, we are trying to create a very simplified rain forecast, which is so ubiquitous that it is easy to overlook its monumental value: the power of predicting the future from heaps of data. But hey, don’t be fooled by its simplicity because the ability to predict is the only thing that matters, not a fancy ML algorithm or a brain-teasing technique!
Before we go crazy with those exciting Machine Learning stuffs, here are 3 things you need to set up.
- Create a project on Google Cloud Platform
- Create a dataset on BigQuery
- Download the below 2 CSV files and upload them to Google Cloud Storage

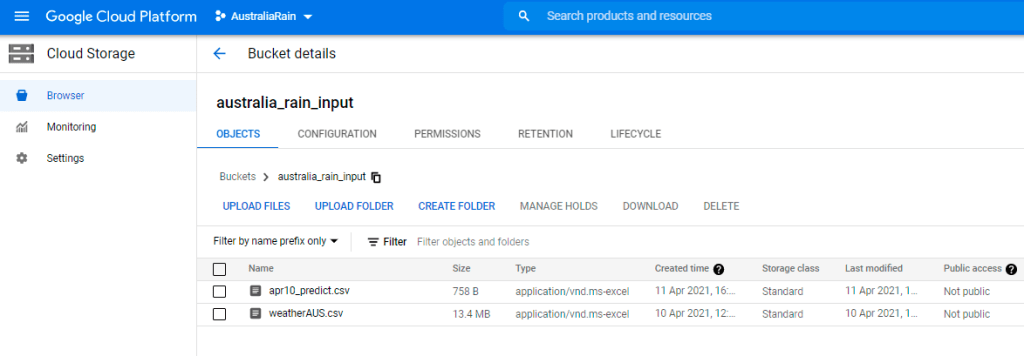
Ingest and split the dataset
Ingest the dataset
Step 1. Load 2 CSV files from Cloud Storage into BigQuery
Since the weatherAUS dataset has null values written as the “NA” string, I will use the bq load command to directly import “NA” strings as null with the null_marker option. Here is how to do it.
On the GCP Console, click the Activate Cloud Shell button at the top of the page to provision your Google Cloud Shell machine. Give it a minute or so to load.
To load the weatherAUS dataset, enter the below command but remember to update the Cloud Storage URI (which starts with gs:// and ends with .csv) since your CSV file will locate at a different location.
bq load --autodetect --null_marker="NA" --source_format=CSV rainprediction.weatherAUS gs://australia_rain_input/weatherAUS.csv
When you see the pop-up window asking to authorize Cloud Shell, click Authorize.

Wait until you see the Current status: DONE, then enter the next command to load the apr10_predict dataset. But don’t forget to update the Cloud Storage URI too.
bq load --autodetect --source_format=CSV rainprediction.apr10_predict gs://australia_rain_input/apr10_predict.csvUpon seeing the Current status: DONE for this loading job, refresh your browser.

Double-check whether you can see 2 new tables called weatherAUS and apr10_predict under your newly created dataset in BigQuery.
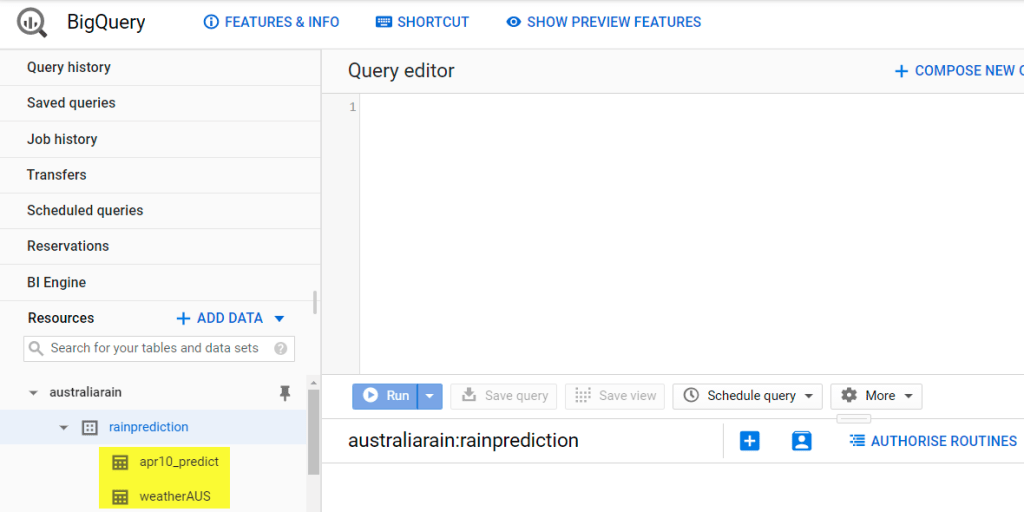
Step 2. Review the data loaded into BigQuery
A quick Preview for the weatherAUS table reveals that there are 145,460 rows of data. The label (i.e. what we are trying to predict) is RainTomorrow and all other columns are predictors (i.e. what variables we might use to predict whether it will rain the next day).
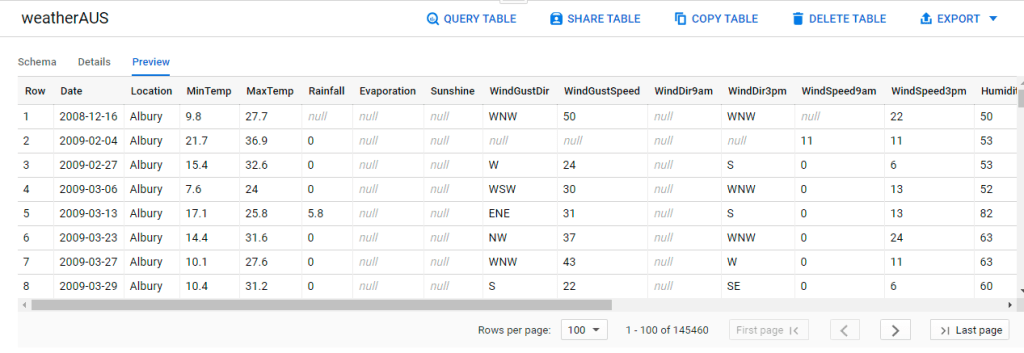
Don’t forget to review the Schema to validate the data type. In BigQuery ML, it always pays to make sure the data type of each column is correct.
Why so? Because different data types would result in very different data preprocessing treatments that are performed automatically by BigQuery ML. Simply put, mixing up data types could result in suboptimal data processing treatments, which eventually hinder the ML model’s accuracy.

In our case, it seems a little odd for numerical values such as MinTemp, MaxTemp, Rainfall, Sunshine and so on to have STRING type. Just keep that in mind as we will fix it in the next section.
Split the dataset into training and test sets
Next, we will split our dataset into a training set and a test set.
- Training set: to train a classification model that maps the given weather observations to the stipulated label (i.e. RainTomorrow).
- Test set: strictly for evaluating whether the ML model can predict with fresh data that hasn’t been seen before by the model
Step 1. Create a fake unique ID column and correct data types for numerical values
#standardSQL
CREATE OR REPLACE TABLE
`australiarain.rainprediction.weather_data` AS (
SELECT
# Create a fake unique ID column to facilitate random splitting
GENERATE_UUID() AS UUID,
# Correct datatype of numerical values from string to float64 or int64 type
CAST(MinTemp AS float64) AS MinTemp,
CAST(MaxTemp AS float64) AS MaxTemp,
CAST(Rainfall AS float64) AS Rainfall,
CAST(Evaporation AS float64) AS Evaporation,
CAST(Sunshine AS float64) AS Sunshine,
CAST(WindGustSpeed AS float64) AS WindGustSpeed,
CAST(WindSpeed9am AS float64) AS WindSpeed9am,
CAST(WindSpeed3pm AS float64) AS WindSpeed3pm,
CAST(Humidity9am AS float64) AS Humidity9am,
CAST(Humidity3pm AS float64) AS Humidity3pm,
CAST(Pressure9am AS float64) AS Pressure9am,
CAST(Pressure3pm AS float64) AS Pressure3pm,
CAST(Temp9am AS float64) AS Temp9am,
CAST(Temp3pm AS float64) AS Temp3pm,
CAST(Cloud9am AS int64) AS Cloud9am,
CAST(Cloud3pm AS int64) AS CLoud3pm,
# Include the remaining non-numerical values
Date,
Location,
WindGustDir,
WindDir9am,
WindDir3pm,
RainToday,
RainTomorrow
FROM
`australiarain.rainprediction.weatherAUS`);
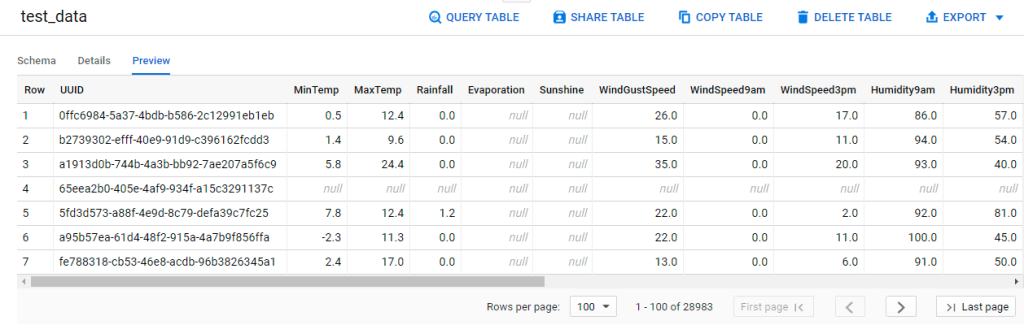
Step 2. Split the dataset based on the fake unique ID column (UUID)
To obtain a repeatable sampling of data for my training and test set, I am using the below BigQuery code by Christy Bergman.
#standardSQL
# Create the test set
CREATE OR REPLACE TABLE
`australiarain.rainprediction.test_data`AS
SELECT
*
FROM
`australiarain.rainprediction.weather_data`
WHERE
MOD(ABS(FARM_FINGERPRINT(UUID)), 5) = 0;
# Create the training set
CREATE OR REPLACE TABLE
`australiarain.rainprediction.train_data` AS
SELECT
*
FROM
`australiarain.rainprediction.weather_data`
WHERE
NOT UUID IN (
SELECT
DISTINCT UUID
FROM
`australiarain.rainprediction.test_data`);
Train and evaluate a classification model
Train an ML model with CREATE MODEL
Train a simple logistic regression model
Now comes the most exciting part yet! Let’s create a logistic regression model, which is the simplest model type for classification problems. Drum Roll, everybody!
#standardSQL
CREATE OR REPLACE MODEL
`rainprediction.logreg` OPTIONS (MODEL_TYPE = 'LOGISTIC_REG',
INPUT_LABEL_COLS = ['RainTomorrow']) AS
SELECT
* EXCEPT(UUID)
FROM
`australiarain.rainprediction.train_data`
WHERE
RainTomorrow IS NOT NULL;
After running the above statement in BigQuery, we will obtain our very first classification model that maps weather observations to either Yes or No for RainTomorrow. Ta-da!

Customise a logistic regression model
It’s no secret that many savvy ML engineers love their freedom of choice when optimizing their models. But on the flip side, having to make so many choices (e.g. learning rate, how and at what fraction to split input data into training and evaluation sets and many many more) can be intimidating if you are an ML newbie or when it’s crunch time.
Fortunately, BigQuery ML has already assumed certain settings as default. As you can see from the example above, without having to deal with a myriad of choices, it’s relatively easy to get a decent ML model up and running in just a few lines of code.
But what if we want to customize certain settings to suit our needs? Let’s experiment with customizing our logistic regression model to reflect 3 changes.
- Randomly sample 20% of the training data to be used for evaluation (Currently BigQuery ML uses only 10,000 rows for evaluation since our dataset has more than 50,000 rows.)
- Correct the imbalanced training dataset (The default option is not to balance the weights.)
- Apply L2 regularization to penalize complexity, thus controlling overfitting (The default option is without L2 regularization.)
#standardSQL
CREATE OR REPLACE MODEL
`rainprediction.logreg2` OPTIONS (MODEL_TYPE = 'LOGISTIC_REG',
INPUT_LABEL_COLS = ['RainTomorrow'],
# Correct the imbalanced training dataset
AUTO_CLASS_WEIGHTS = TRUE,
# Assign 20% of training data for evaluation
DATA_SPLIT_METHOD = 'RANDOM',
DATA_SPLIT_EVAL_FRACTION = 0.2,
# Apply L2 regularization
L2_REG = 0.1) AS
SELECT
* EXCEPT(UUID)
FROM
`australiarain.rainprediction.train_data`
WHERE
RainTomorrow IS NOT NULL;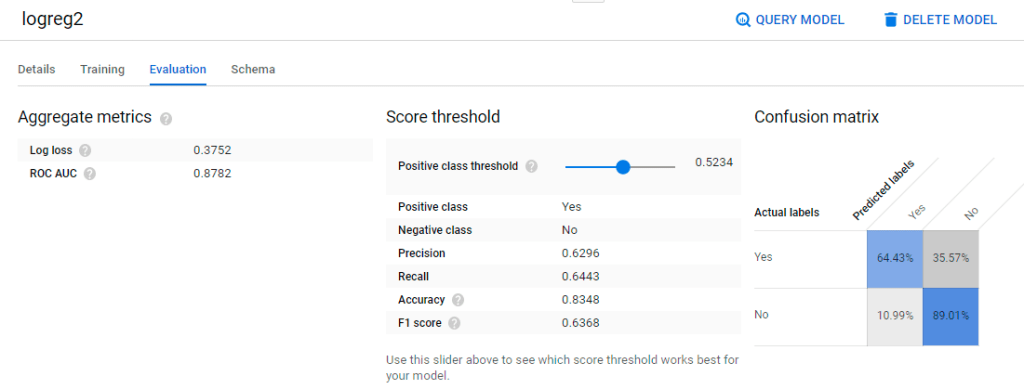
Oh, wait! Does it mean we can customize everything and anything? Nope. At least not for now, but feel free to check out BigQuery documentation to learn what you can’t customize and experiment with what you can.
Evaluate classification models with ML.EVALUATE
It’s time to use the test dataset to validate the performance of our very first and simple logistic regression model. Let’s see how well such a straightforward model (without any fancy fine-tuning) can predict RainTomorrow with fresh data that hasn’t been seen before.
The query can’t get any simpler than this.
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `rainprediction.logreg`,
(
SELECT
* EXCEPT(UUID)
FROM
`australiarain.rainprediction.test_data`));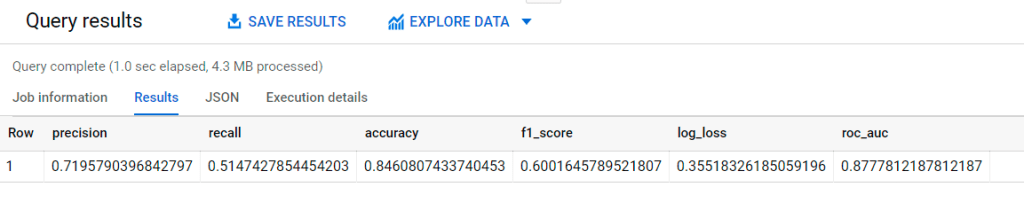
Since the ROC_AUC of the test set (0.878) is almost the same as the ROC_AUC of the training set (0.880), our model is not overfitting. The accuracy of 0.85 also looks decent. Of course, more feature engineering with the TRANSFORM clause could be done to improve the overall F1_score but for now, let’s stick to what we have.
Predict next-day rain with the classification model
In the apr10_predict table, I have gathered daily weather observations across several locations in Australia on 10 April 2021. Next, we shall use our logistic regression model to predict whether it will rain on 11 April 2021.
#standardSQL
SELECT
predicted_RainTomorrow, predicted_RainTomorrow_probs, Date, Location
FROM
ML.PREDICT(MODEL `rainprediction.logreg`,
(
SELECT
* EXCEPT (RainToday),
CAST(RainToday AS STRING) AS RainToday
FROM
`australiarain.rainprediction.apr10_predict`), STRUCT(0.6 AS threshold));
Let me explain what’s happening with the screenshot above.
- The predicted_RainTomorrow shows whether it is likely to rain on 11 April based on a 0.6 threshold that I have chosen. As long as the probability of “raining” exceeds 0.6, the model would predict “RainTomorrow” = Yes for the next day.
- The next two columns predicted_RainTomorrow_probs.label and predicted_RainTomorrow_probs.prob shows how BigQuery arrived at the prediction. In the first row, the model calculated that the probability of “not raining” for Sydney is 0.75 while the probability of “raining” is only 0.25. Since the probability of “raining” is below the threshold of 0.6, the prediction for next-day rain is “No”.
- The final column in red is something I have added to the screenshot so that you can easily compare the prediction and the actual rain on 11 April. This is NOT what the model would give you when executing the query.
If you are still wondering what threshold means in classification models, check out this simple explanation. But as far as the prediction goes, we only got it wrong for Darwin. I would say this is not bad, given we only spend very minimal time writing simple queries in Google BigQuery.
When time is of the essence and your data is readily available in BigQuery, this is it – BigQuery ML is the way to go!
Wrapping Up
So there you have it, a quick tour of how to train and evaluate a classification model as well as predict next-day rain with BigQuery ML! Can BigQuery ML replace other industry-standard machine learning frameworks like Tensorflow, Keras and so on? Probably not because making ML works in real life is a series of trade-offs between competing objectives such as speed, simplicity and accuracy.
If you are a savvy ML engineer who prefers a great deal of freedom to experiment with various ML models and different data preprocessing techniques to achieve extremely accurate predictions, you might be better off looking elsewhere. It is because BigQuery ML currently offers limited choices as it retains its simplicity and speed.
However, being someone who appreciates the ability to quickly test out a new idea or create a good enough ML baseline model, I do see the value of BigQuery ML. I don’t have to fuss around trying to export data from the data warehouse since I am training and deploying ML model right inside BigQuery, the data warehouse itself. Also, there is no need to build a full-fledge ML pipeline using Python or Java because I can use SQL to create a model with several lines of code. What’s not to love?
Thank you for reading. Have feedback on how I can do better or just wanna chat? Let me know in the comments or find me on LinkedIn. Have a fabulous week everyone!
