

Began as the storage system for the web search index at Google. Made available as a public service via Google Cloud Platform in 2015 and currently powers some of the most prominent web and mobile applications such as Spotify, Google Maps and Google Search. It’s no other than Cloud Bigtable, which is neither suitable for complex joins, ad-hoc interactive queries nor ideal for supporting an online transaction processing (OLTP) system.
So what is it and why might we need a massive database like Cloud Bigtable one day?
You’ll learn:
- The real-world challenge: Site speed and personalisation customer engagement
- A primer to Cloud Bigtable: Definition, good fit versus bad fit
- Key concepts for Cloud Bigtable
The real-world challenge: Site speed and personalisation for customer experience
Before jumping into the technology side of things, I think it’s useful to start with the business context and uncover how customers’ expectations drive the needs for handling massive real-time analytics workload. So here we go!
Customers’ expectations for instant gratification and individuality
It’s difficult not to notice that our customers are always on the go, has very little patience and won’t settle for a less than amazing customer experience. Here are 2 things customers have come to expect when accessing any mobile sites or apps.
- I want it now
- I want it personalised to my taste and preferences
According to a Deloitte study in 2020, a mere improvement of 0.1 seconds in site speed could result in 7% more leads generated and almost 10% more spending.
Another 2019 market research reported that 63% of smartphone users are more likely to purchase from companies whose mobile sites or apps offer them relevant recommendations on products they may be interested in.
Simply put, how fast your mobile applications load and how personalised the content shown greatly influences how engaged your customers are and whether they decide to purchase on your site or not.
Database capabilities to handle massive real-time analytics workloads
But what does personalisation means for mobile sites and apps?
A great example is the Spotify music app. As soon as you open Spotify, the Home page displays personalised content such as Recently played songs and Top shows related to your user profile as well as recommends Daily Mixes and Discover Weekly music to help you discover new music based on previous songs you listened to.
Another common use cases are e-commerce sites. You can easily find personalised product recommendations such as “Others you may like”, “Frequently bought together”, and “Recommended for you”.
Here is the tricky part: All of these have to happen automatically within milliseconds. Because life is too short to keep our precious customers waiting and even 1 second feels like forever in this age of instant gratification, am I right?
But building such robust mobile sites or apps to automate the massive real-time analytics workloads for personalised recommendations is never an easy task. And believe it or not, it all starts with a database, or dare I say, a very special type of database that looks nothing like the all too familiar relational databases. Below are the key capabilities that the ideal database has to offer.
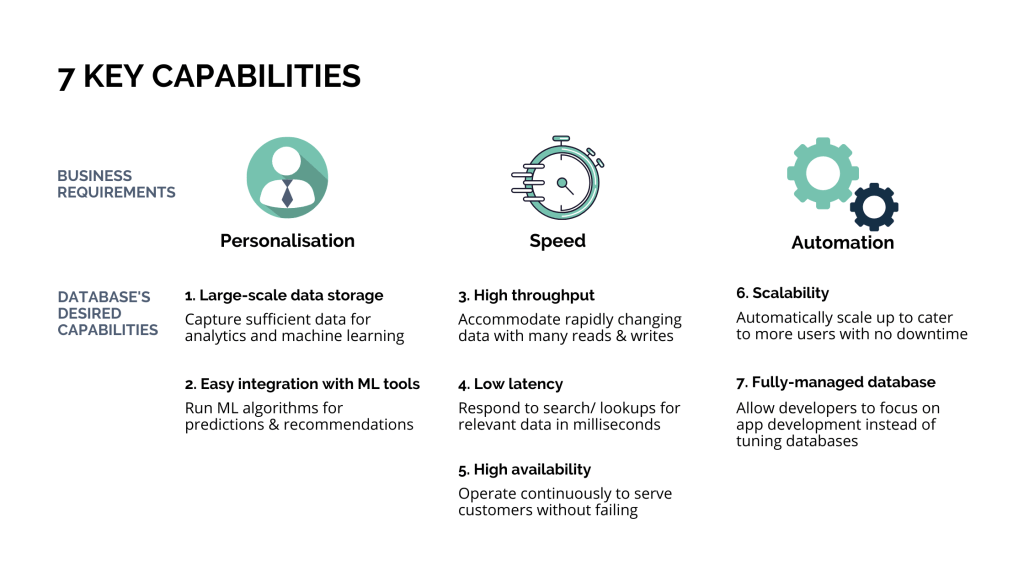
And when it comes to existing databases offering all 7 key capabilities, the two most well-known examples include Amazon DynamoDB and Google Cloud Bigtable. Let’s explore Cloud Bigtable today and save Amazon DynamoDB for another day.
Ten-second takeaway
Being a proud member of the powerful NoSQL database family, Cloud Bigtable offers great capabilities to power mobile sites or apps with personalisation, speed and automation.
A primer to Cloud Bigtable
Cloud Bigtable is a sparsely populated table that can scale to billions of rows and thousands of columns, enabling you to store terabytes or even petabytes of data.
From Google Cloud
First and foremost, it’s important to note that Cloud Bigtable is not a relational database. It neither supports ACID transactions nor SQL queries. This renders Cloud Bigtable unsuitable for both OLTP and OLAP system.
Also, Cloud Bigtable is incredibly powerful, sometimes to the extent that it’s likely an overkill or way more expensive than what you need for small-scale applications or toy projects.
If you’re wondering whether you would ever need Cloud Bigtable, here are some helpful considerations I have summarised from the book “Google Cloud Platform in Action” by John J. Geewax.
| Considerations | Good Fit | Bad Fit |
| Data Volume | Terabytes or more | Within the gigabyte range |
| Data Structure | Key/ value data | Structured data with a strict requirement for relational schema |
| Speed | Data should be captured and processed in milliseconds | A bit of latency is fine |
| Throughput | Need to cater to thousands of requests every second concurrently | Only a few queries per second |
| Query Complexity | Simple lookups or scans across keys are sufficient | Complex joins and SQL queries are needed |
| Cost | Willing to pay a lot for large-scale data storage with low latency and high throughput | Minimal budget for proofs-of-concept or toy projects |
Ten-second takeaway
Cloud Bigtable is a large-scale data storage solution that offers great speed and high throughput at the expense of query complexity and cost.
Key concepts for Cloud Bigtable
Being a NoSQL database that is built to support massive analytics workloads, Cloud Bigtable has many unique characteristics that set it apart from the usual relational databases.
Among all characteristics, here are two key concepts that we should understand at the bare minimum.
Optimise data processing with 3D Map Structure

Take a look at the picture above, what can you see?
The picture represents how data is stored in 2 dimensions (rows and columns) in a Cloud Bigtable table. Well, very similar to relational databases right?
Don’t jump to a conclusion too soon. Things are slightly more complicated than it looks. So let me explain what’s going on.
First dimension: Rows
Each row is uniquely identified or indexed by a single row key. Simply put, a row key is analogous to a primary key in relational databases. Data stored in Cloud Bigtable is automatically sorted by row key in alphabetical order (a.k.a. lexicographically sorted), which makes search and scan across the table much faster.
Second dimension: Columns
Related data is then grouped into column families. For example, a user’s basic profile information (e.g. name, email address, mobile number) could be grouped into a family while the user’s comments can be grouped into another family. The purpose is to gather all information frequently retrieved together in the same place, thus making lookups more efficient.
Each column under the same family has a unique column qualifier. Similar to the row key, columns within the same family are also sorted by their column qualifiers in alphabetical order to improve query speed.
Here are 2 points to note about Cloud Bigtable columns.
- No two column families in the same table should share the same family name. Also, no two columns in the same family should share the same column qualifier. Therefore, each column is uniquely identified by a combination of the column family name and a column qualifier.
- If a column does not contain any data in a particular row, it does not take up any space or storage. That’s why we say Cloud Bigtable tables are sparse.
Now we know rows and columns are the first two dimensions of the 3D map structure in Cloud Bigtable. But where is the third dimension? Let’s find out.
Third dimension: Cells

It might take a bit of imagination, but the above picture might help you along. If we look up by a specific row key and zoom into a specific column, normally we would expect to find a single value.
But in Cloud Bigtable, we would find different versions of the value at different points in time. Each timestamped version is called a cell, which is the third dimension we are looking for.
So why bother having this third dimension and making things complicated?
Remember the data being stored in Cloud Bigtable is expected to change rapidly over time. For example, a customer may click to view a product then quickly move on to the next. A user might listen to a song for 10 seconds, doesn’t find the tune suitable for her mood and press Next.
But we want to easily see the history of the data in a row such as what products a customer has viewed since last week, which songs a user listened to yesterday, how the customer’s music genre has evolved.
With the third dimension, businesses can effectively go back in time, pull out relevant past interactions for analysis and display personalised content or recommendations in milliseconds. That’s what makes Cloud Bigtable the almighty database powering mobile sites or apps with speed and personalisation.
Beware, the performance of Cloud Bigtable heavily relies on schema design and the choice of row key. If you want to know more about best practices for designing schema and choosing an appropriate row key in Cloud Bigtable, don’t forget to check out this Google documentation.
Enhance performance with distributed processing infrastructure
Instances, clusters and nodes
Admittedly, it took me a while to understand how Cloud Bigtable infrastructure works. Don’t be alarmed as I won’t bore you with too many technical details. To keep things as easy to understand as possible, below is what you need to know at the bare minimum.
There are 3 key components of Cloud Bigtable infrastructure: instance, cluster and node.
- When we say deploying a Cloud Bigtable database, it means creating an instance. It is the giant container holding all bits and pieces of the database. An instance can contain one or many clusters.
- Each cluster denotes a specific location to store your data. Under each cluster, there could be one or many nodes.
- Each node is responsible for managing how data is written and queried inside the database.
Performance implications

Scenario 1: 1 Cluster, 1 Node
Scenario 1 illustrates the simplest and cheapest form of a Cloud Bigtable instance. You could deploy an instance with 1 cluster and 1 node. But wait! Because you could doesn’t mean you should.
Having 1 cluster and 1 node might be okay for some experiments or a (fairly expensive) pet project. However, if you have too much data generated and queried from the front-end applications, the single node might easily be overloaded and slowed down significantly. Also, having 1 single cluster is like putting all your eggs in one basket. If the cluster becomes unavailable due to technical issues, related applications will fail too.
Scenario 2: 1 Cluster, N Nodes
Simply adding more nodes under the same cluster will take us from scenario 1 to scenario 2. With these additional nodes, you can handle more requests to write and read data, thus enjoying better performance. This is especially useful to scale up to handle the ever-growing demand for data processing.
However, having a single cluster means all data is only available in a single zone. Should any incident happen within this geographic location (e.g. power outage), your database and applications would go down as well. Unquestionably a critical risk to consider since we all want our mobile sites or apps to operate continuously without failing, am I right?
Scenario 3: N Clusters, N Nodes
Scenario 3 is where Cloud Bigtable unleashes its full power. With multiple clusters in place, any change to the data made in one cluster is replicated in other clusters locating at different zones or regions within seconds or minutes. In the event a cluster completely fails, data is readily available in other clusters. Another cluster can quickly take up the workload so that we can do business as usual. A downside to this scenario is money! Having multiple clusters running in parallel certainly requires some hefty ongoing expenses.
Ten-second takeaway
Although Cloud Bigtable is incredibly powerful, it definitely comes with its quirks and requires us to think very differently about how to design and manage our databases for performance and availability.
Parting Thoughts
Once upon a time, we had a little more than gigabytes to work with and things fit nicely into a flash drive. Only a few years ago, a data warehouse requiring a terabyte of storage was enough to make people amazed. Yet it’s very common nowadays for businesses to generate petabytes of data every day. Unsurprisingly, our customers have also come to expect businesses to translate such a massive amount of data into personalised content for a better experience with mobile sites and apps.
As its name suggests, Cloud Bigtable is meant to be the robust database that powers massive real-time analytics workload for mobile sites and apps. Although this blog post barely scratches the surface of what is possible with Cloud Bigtable, I hope I have given you one or two new insights about this one-of-a-kind NoSQL database.
If you’re reading this, thank you for your time. Feel free to connect with me on LinkedIn and Twitter and let me know how I can do better next time. Take care, stay safe and keep being awesome!
