

Time series analysis is like air
Imagine a world where time series analysis doesn’t exist! Those painful booms and bust cycles of the economy might sound like random challenges that life throws at us. Governments would have a hard time trying to forecast the economic growth while companies struggle to predict future demand to plan for production.
On a more personal level, you might leave the house only to drive straight into the path of a hurricane because the weather forecast doesn’t even exist. Yikes!
People have been observing how natural phenomenon or social behaviour change with time for ages. In ancient China as early as 800BC, astronomers started recording sunspot time series, making it one of the most well-recorded natural phenomena ever.
After studying the death records in London, John Graunt, a 17th-century dealer created the first actuarial life table which shows the probability that a person of a given age will die before their next birthday. Guess what? Life insurance companies still use actuarial life tables (a more sophisticated version than the 17th-century table of course!) to decide how much they should charge us for insurance premium every year till today.
Time series analysis is like air. We don’t really notice it until it’s gone – and then it’s all we notice.
What’s more? Having some basic understanding of time series is extremely useful if we want to predict the future based on what happened in the past. Therefore, this post is a simple introduction to time series analysis and its core concepts.
Even if you hate maths, not a fan of statistics, but simply want to learn one or two new things, then don’t be scared. Let’s roll!
What is time series analysis and why do we need it?
This is Aria. Her 2021 New Year’s Resolution was to create a budget and track her daily expenses. So here is a snapshot of what she has recorded for the week between 17 May and 23 May, together with some questions she wanted to find out for herself.

What Aria has done is to create time-series data to monitor how her daily expenses fluctuate over time. This would help Aria to understand her spending habits during the week, estimate next week’s spending and assess how she should adjust her spending to stay within the monthly budget.
Simply put, time series analysis is all about examining the movement of a numeric value over time. The goal is to understand the overall trend, verify different hypotheses about what happened and most importantly forecast what the future might look like.
What kind of data do we need for time series analysis?
To conduct time series analysis, we will need time-series data. But beware! Some data types might look like time-series data, but they aren’t. So let’s clarify exactly what time-series data is and is not.
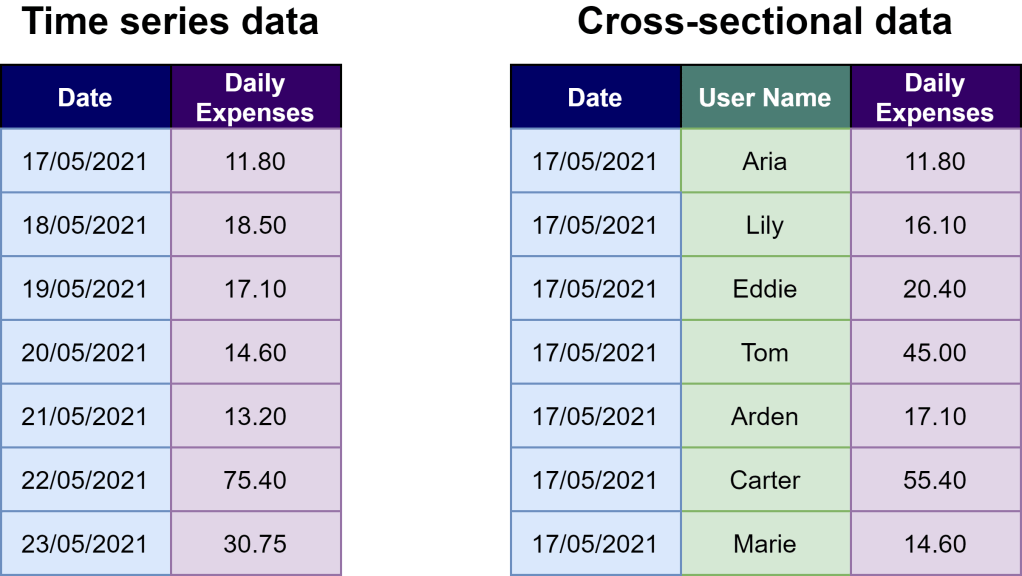
On the left, we have a table that tracks Aria’s daily expenses from 17 May to 23 May. Time series data is a collection of observations about the same case across different points in time. It has to be ordered chronologically and are assembled over even intervals in time. Daily expense, or whatever numerical value we’re interested in tracking over time, is called a time series variable.
On the right, the table includes not only Aria’s daily expense but also 6 other people on 17 May. This is cross-sectional data that reflects observations from multiple cases from the same point in time.
Why is it important to distinguish between time series data and cross-sectional data? Because cross-sectional data are from different cases, which could be unrelated (or independent) to the case we are interested in. In this case, if Aria is mainly concerned about her spending habits over time, having cross-sectional data on how the other 6 people spent their money on the same day is not helpful at all.
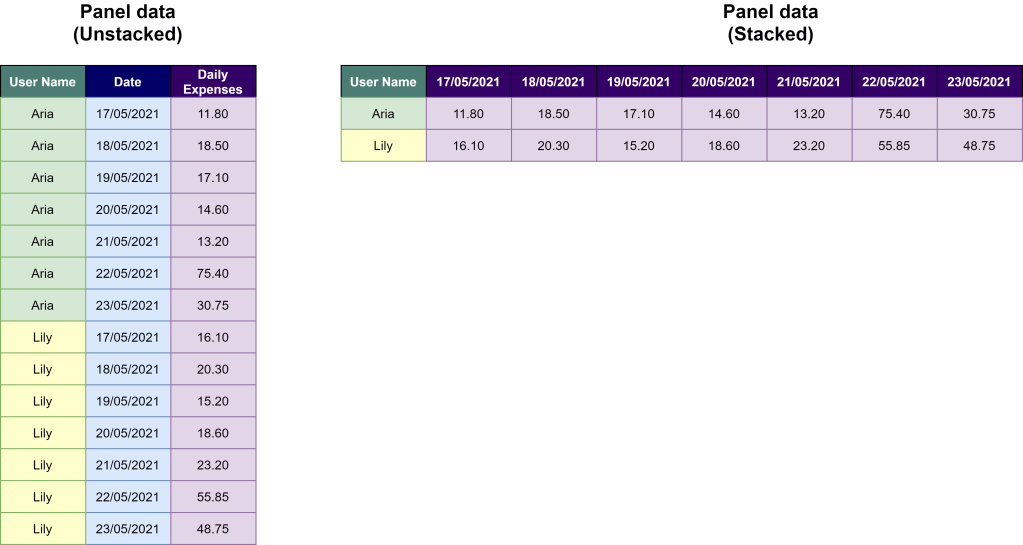
The picture above showed another type of data that could easily be mistaken for time series data. Here, we have the daily expenses of Aria and Lily between 17 May and 23 May. The left side represents the narrow (a.k.a. unstacked) form while the right side illustrates the wide (a.k.a. stacked) form.
Both stacked and unstacked forms represent panel data, which consists of observations about multiple cases at multiple points in time. The key point to remember here is that in panel data, we have more than one case. So do remember to check which case you want to examine further with time series analysis. You might either need to filter data to remove irrelevant cases or summarise the data for a more aggregated view.
Ten-second takeaway: Is your data already in time-series format or do you need to transform it to a more usable form?
What is stationarity and why does it matter?
Remember we said earlier that one of the goals of time series analysis is to predict or estimate the future value of a time series variable (let say a variable Y)?
But what can be a good estimator of the future value of Y? Well, we have so many options. One of the easiest and simplest options is to use the mean (a.k.a. average).
However, for this approach to be valid, we must assume that over time the future value of a time series variable converges on a single value, which is the mean of Y. This brings us to the idea of stationarity, which encompasses the following 2 points.
- The mean and variance of Y have to stay the same over time.
- Any fluctuation in Y value occurs randomly. The rise and fall of Y don’t relate to time.
Only when the time series of Y is stationary, we can then estimate the future value of Y based on the mean of Y that we calculated from known observations as of today.
What if the time series is not stationary? We can either apply transformation (e.g. difference or logarithmic transform) to convert it into a stationary time series or opt for other approaches that are more suitable for a nonstationary dataset.
Ten-second takeaway: Before deciding on how to best estimate the future value of time series, have you checked whether the time series data is stationary or not?
What makes a time series nonstationary?
Now comes the tricky part! There is only one way for time series to be stationary. But there are so many ways for time series to be non-stationary.
Here, we’ll explore the 3 most common reasons including trending, periodicity and structural breaks. But do keep in mind these aren’t the only factors resulting in non-stationarity.
Trending
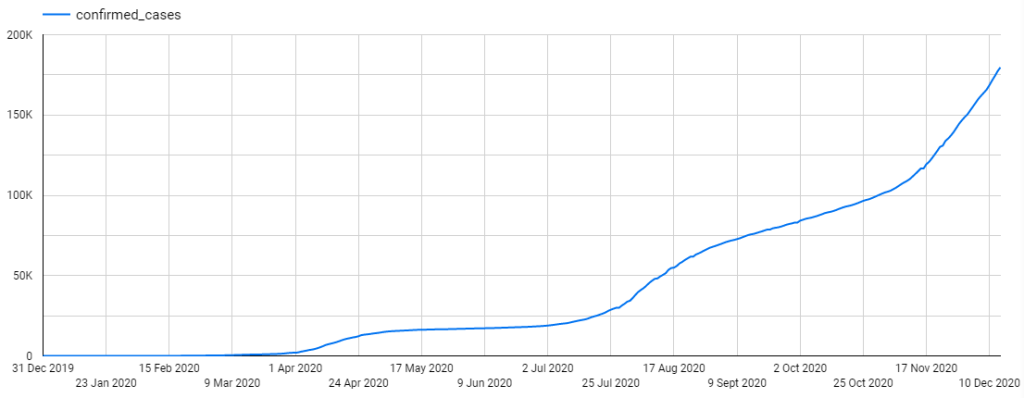
Trending means the time series exhibits an upward or downward movement over a long period. Following this trend, the mean of the time series also keeps increasing or decreasing in the long term. Thus the time series is no longer stationary and the mean is not a good estimator for future value.
As shown above, the easiest way to spot trending is to use a time-series plot (a.k.a. line plot, time-series graph). One axis represents time while the other axis shows the numeric values.
However, sometimes, within the short term (e.g. between 31 Dec 2019 to 9 Mar 2020), the general trend might not be evident. Therefore, it can be easily mistaken for a stationary time series. To recognise the general trend of time series, it is recommended to observe time series plot over a longer period such as multiple years.
Periodicity
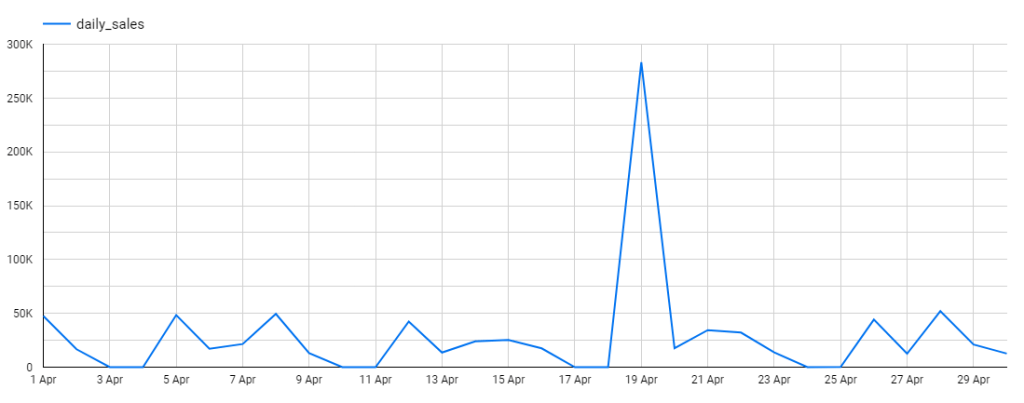
Periodicity means the ups and downs follow a cycle and are repetitive over time. In the picture above, it’s not difficult to guess because the wholesale stores under Iowa’s Alcoholic Beverages Division close every Saturday and Sunday. Therefore daily sales are zero during weekends.
If those rises and falls align with the calendar (e.g. month, quarter, season, public holidays etc.), then periodicity has another name, which is seasonality. For instance, retail sales revenue often rises during the Christmas period while temperature usually dips below zero during winter in Canada.
With periodicity, the mean of the time series changes in tandem with time or season. Thus, an easy way to detect seasonality is to observe the line plot to spot peaks and troughs that are regularly spaced and follow approximately the same direction as well as magnitude every year. Another way is to create multiple box plots to visually compare mean value across different months or quarters.
Structural Breaks (a.k.a. Equilibrium Shifts)
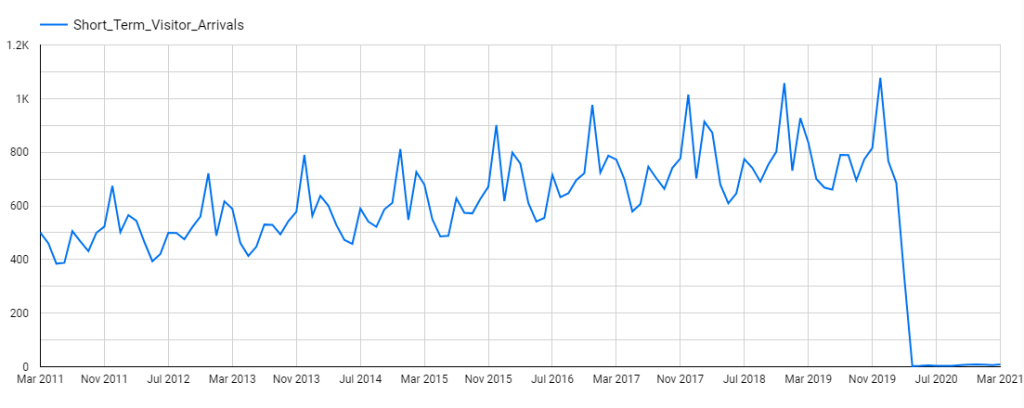
While trending and periodicity exhibit somewhat systematic and predictable changes, structural breaks reflect abrupt changes at a point in time. For example, when Australia closed its border last year due to COVID-19, the short-term visitor arrivals to Australia plummetted by 97.5%.
No doubt the mean of the time series also shifted to a new level. This also suggests that the mean value based on past observations is no longer a good estimator for the future. Whenever this happens, it’s time to revise the model to account for the underlying shift and the related factors.
Ten-second takeaway: Does plotting your time series data reveal any trends, periodicity or structural breaks? If not, have you conducted the Augmented Dickey-Fuller test or KPSS test to check for stationarity?
What are the common approaches for univariate time series analysis?
There are many ways to predict future values of time series analysis. Supervised machine learning methods are often used when the time series has more than one variable collected over time. This is also known as multivariate time series. But let’s save this for another day.
For univariate time series analysis, only one single observation is collected over time. For example, scientists have been measuring CO2 in the atmosphere at Mauna Loa Observatory in Hawaii since 1974 for research purpose.
When the time series data only consists of one single column of numbers against time, the simplicity of classical time series methods could truly be a blessing. Therefore, many classical time series forecasting methods could be great alternatives to machine learning methods for univariate time series analysis.
Here, I will briefly introduce the logic behind 3 classical time series forecasting methods. Just in case you want to know more about other classical methods, here is a short and sweet article to explore.
Moving Average (MA) Model
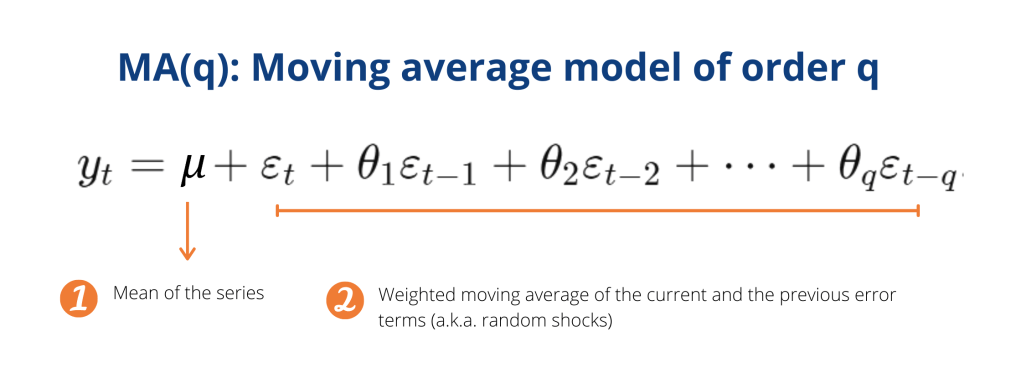
Take a look at the image above! What can you see? Complicated? Scary? Don’t fret. Essentially there are only 3 points you need to understand.
Firstly, a moving average model is essentially a two-part mathematical formula.
The first part says we can calculate the future value of a time series based on its mean value. But remember we spoke about this earlier? For the mean to be a good estimator of future values, the time series itself has to be stationary. So it’s important to always check for stationarity first!
Although the mean can predict future value pretty well, we say random shocks might influence future values of the time series well in the future. Hence, we take those influences into account by including the weighted moving average of the current and previous random shocks. That’s what the second part of our formula is all about.
Secondly, q is the order of the moving average model. MA(3) means a random shock will affect the mean of the series for the current period and 3 periods into the future.
Finally, moving average model and moving average (a.k.a. running average, rolling average) smoothing are 2 distinct concepts for totally different purposes. While the former is used to predict future values of a time series, the latter helps to smooth out fluctuations and highlight long-term trends or cycles.
Autoregressive (AR) Model

Well, another mathematical formula to look at! Don’t run away. Because below are the 3 most important points to take away.
Firstly, an autoregressive model is essentially a two-part mathematical formula.
The first part says we can calculate the future value of a time series based on the linear regression of the past value of itself (the “auto” prefix literally means “self” in Greek). For example, this year GDP is likely to be dependent on last year’s GDP.
Although past data can predict future value pretty well, the future value might also be influenced by random or uncertain factors. Therefore, we need the second part to take such uncertainty and randomness into account.
Secondly, p is the order of the autoregressive model. AR(2) means the model calculates the time series variable based on its past value at t-1 and t-2. For example, a monthly sales forecast AR(2) will predict June sales based on May and April historical sales.
Finally, to generate a “good enough” estimation of future value with autoregressive models, the time series itself has to show some structure of autocorrelation. This means correlation has to exist between a given time series and a lagged version of itself over successive time intervals.
ARIMA
What does the ARIMA acronym stand for? It stands for Auto-Regressive Integrated Moving Average. At its core, here are 3 key points to remember.
Firstly, in theory, an ARIMA(p, d, q) models are a generalisation of the Autoregressive model and the Moving Average model to obtain a good estimator for the future value of a time series. p and q are the order of AR and MA models respectively.
Secondly, since the time series has to be stationary for AR and MA models to be valid, non-stationary time series has to undergo differencing one or more times to achieve stationarity. The number of times the series has to be differenced to create a stationary time series is reflected by the parameter d.
Finally, after differencing, the newly created time series is called an “integrated” version of the original one. This explains the letter I in the ARIMA acronym. By including the differencing feature, ARIMA works for both stationary and non-stationary time series.
Ten-second takeaway: Before deciding which approaches work best, have you explored your time-series data to understand its underlying character (e.g. autocorrelation) with ACF plot as well as the real-life context?
Parting Thoughts
So there you have it! A very quick tour that covers some key concepts in time series analysis. I hope these plain English explanations are useful in decoding some of the jargons and mathematical formula that hinders you from appreciating the value of time series data.
You don’t have to be involved in stock markets to be influenced by time series. Weather forecasts, customer purchase history, daily COVID-19 confirmed cases and even your Fitbit health metrics are time series.
Beyond the stock markets, people constantly generate, capture and monitor time-series data in all shapes, forms and across a wide range of disciplines. For better or worse, the insights obtained from time series analysis have the power to inform upcoming personal decisions, business strategies, public policies or global changes that might affect everyone of us.
Thank you for reading. Have feedback on how I can do better or just wanna chat? Let me know in the comments or find me on LinkedIn. Long live and prosper, everybody!
References
- Practice Time Series Analysis by Aileen Nielsen
- Forecasting: Principles and Practice by Rob J Hyndman and George Athanasopoulos
