

If you ever tried to read articles about metadata on the Internet, you would most likely come across either the horror stories (something around the line of new metadata retention laws with creepy security loopholes that would screw us all) or the utopian fairytales (hey, metadata is the magical silver bullet for data democratisation and making your analytics dream come true).
While metadata seems to be moving the world, it secretly blends into the background, remains quiet and is taken for granted until something blows up.
For better or worse, metadata will always be part of the balancing act between extracting value from data and ensuring proper governance. And this is just a simple story for those who always wanted to understand what metadata is, why it matters in the big data world and how we should start thinking about it. Forget about those mind-bending jargon or unrealistic myths, let’s begin.
In this post, you’ll learn:
- What is metadata?
- Big data, data lake and metadata
- Three types of metadata
- Roadblocks to metadata management
What is metadata?
Let’s begin by properly defining what metadata is. I bet you might have already come across this all-too-familiar definition: metadata is “data about data”. Hmm, not very helpful, right?
I personally love the below definition as it captures both the definition and the purpose of metadata.
Metadata is the structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use or manage an information resource.
National Information Standards Organisation
If you are shopping for groceries in the supermarket, metadata is the nutritional information on the package. If you are looking for the next pair of shoes via an online shop, the product image, size, colour, brand and price tag are metadata about the product itself.
In the business context, if you are sending an email to your colleague, the “from” and “to” email addresses, the subject and the sent date is the metadata. If you wish to locate a specific Excel file containing the latest product list on the team’s OneDrive, the file name, the “Last Updated” date and the file type are valuable metadata to help you pinpoint exactly what you need.
Metadata is everywhere. But I hope you are seeing the pattern here. Metadata doesn’t represent a subjective opinion about an item. Instead, it captures a fairly objective description about a resource that is readily available and meant to be shared by more than one person.
Big data, data lake and metadata
Data lake: The one-stop online shop for big data
The notion of sharing resources within a business and across different organisations to save time and improve productivity isn’t new. The same logic also applies to big data.
Given the appropriate approvals and access rights, if Simon needs the latest list of customers, and Fiona has worked so hard to create that perfect list for her project, then Simon shouldn’t waste his time reinventing the wheel. Instead, he should reach out to Fiona and reuse that list for his analysis on how to generate new revenue streams or enhance customer experience.
Such an idea works perfectly for a small team where everyone knows each other. But in larger organisations with hundreds of employees and thousands of datasets, it would be a nightmare to ask around who have what. So many businesses opt to build a data lake.
What is a data lake? Well, a data lake is like a department store. You get pretty much everything you need for your family (e.g. clothing, shoes, beauty products, toys, gifts, etc.) in one giant store without having to run around like a headless chicken across dozens of shops.
Similarly, a data lake allows you to access different information resources via a one-stop-shop for analysis and decision-making. With the data lake, different users can share and reuse information resources (e.g. such as text, images, videos, reports, dashboards, datasets, code snippets, etc.). Since most of the time spent on data analysis projects is related to identifying, cleansing, and integrating data coming from different sources, the investment in building a data lake could be worthwhile.
Metadata: The secret ingredient of a functional data lake
A messy storage space
Let’s assume that after some hefty investments and agonising teamwork, we now have a data lake. All sorts of data are nicely stored in single storage space, waiting for you to discover.
You want to look for the latest list of customers as of August 2021. So you eagerly access the location of the data lake, do a search and here is what you find.

Have you ever found yourself stepping inside a shop that looks like a maze, not able to find what you need and eventually walk away? The same thing could happen here with our very dear data lake when everything looks equally confusing and ambiguous. Since we don’t have the magic mirror on the wall, most people would walk away from a messy storage space if it were too painful to find what they need.
A pleasant shopping experience
People are impatient and expect nothing less than instant gratification. We need to make it quick and easy for them to identify and locate what they need. So let’s reimagine the search of data as the most pleasant online shopping experience you ever experience. How would it look like?
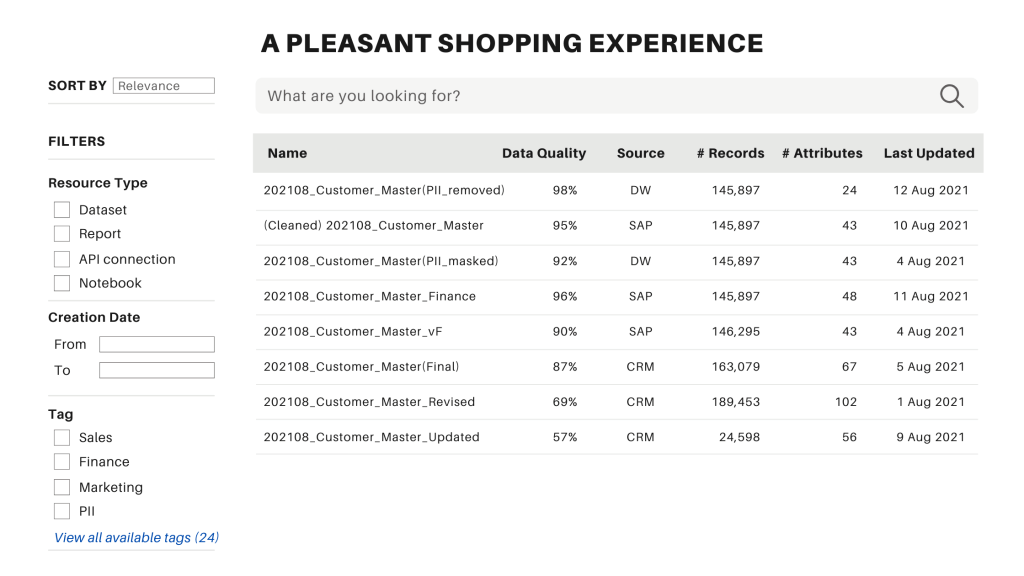
A simple UI like the one shown above to search, sort, filter and locate what data you need is often called a data catalogue (or data catalog), which somewhat resembles a modern online shopping site.
Now we still have the same set of 8 possible datasets, but we also have more information about each resource to differentiate one from others. For example, with metadata indicating data quality, data linage, number of records and other succinct “product descriptions”, you can easily identify what resource is the most relevant and trustworthy for your needs.
What’s more? Upon locating what you need, with metadata about who owns the data, you can send a request to obtain the dataset. Many modern data catalogs also rely on metadata about data owners to create automated workflows to request approvals and inquiries. No more endless back-and-forth emails that often get us to nowhere!
Other metadata such as the data source, storage location, format and access rights also enable companies to automate the data provisioning process. You identify what information resource you need, add to cart, check out while a backend process coordinates all the necessary steps to deliver the data straight to your preferred location. Such an “online shopping experience” to self-serve your data needs without any fuss is what people called data democratisation.
Simply put, metadata is the secret ingredient to create a functional and scalable data lake platform. It effectively promotes data resources to the right audience, establishes connections between related resources and creates a “pleasant shopping experience” for data consumers via data catalogs.
Three types of metadata
It’s important to acknowledge that metadata is complex, varied and there is more than one type of metadata. Each of them could serve a very different purpose in understanding and managing information resources. Below is a summary of three main types of metadata according to the Data Management Body of Knowledge.

Looks lengthy and complicated, right? Don’t worry. I only have two key takeaways for you to keep in mind.
Firstly, some metadata could be more relevant for business users who are searching for a dataset while other details dictate how businesses protect sensitive data, comply with privacy laws and mitigate security risks. High-quality metadata not only facilitates data discovery (thus speed up time to insight) but also ensures data governance and risk management.
Secondly, metadata is created, consumed and assessed by different stakeholders within the organisation. Just like too many cooks spoil the broth, metadata could easily become a mess if everyone wants to have his own way. So proper management with careful planning, implementation and control is definitely a must to create and maintain high-quality metadata.
Roadblocks to metadata management
Since metadata management (and how to do it properly) is a topic that deserves its own article, I will save it for another day. But have you ever wonder why the life of metadata remains so secret? A few dedicated teams would occasionally talk about it, perhaps a handful of people know what to do with it, and only the most privileged people in the organisation are thinking about how to manage it.
If high-quality metadata matters so much for anyone who works with data in your organisation, why aren’t we giving metadata the attention it deserves?
Well, there is a myriad of reasons to stay ignorant about metadata, let alone taking on new initiatives to manage it. Here are two major roadblocks for metadata management initiatives that you should be aware of.
Unclear tangible benefits and incentives

You might possess the greatest passion and amazing ideas to help your company manage metadata the right way. But don’t forget your company has a limited amount of time and money while there’s no shortage of pressing issues.
Hence, creating and managing metadata for its own sake rarely works well. At the end of the day, none of those initiatives matters if it doesn’t help the business to solve any top-priority problems.
When neither clear tangible benefits nor critical risks exist to justify the investments for metadata management, don’t force it to be the agenda. Instead, you might want to just keep metadata management in mind. Because sooner or later, as the organisation handles and analyses a greater deal of data, metadata management would become the elephant in the room that no stakeholders could afford to ignore.
Metadata management requires people to change how they interact with data on a daily basis. The problem is, even when the benefits and risks are obvious for some people, others might not feel the need to follow a new process or do things differently. After all, people in different roles have very different needs.
So why is metadata management necessary for the organisation’s survival or growth? More importantly, what’s in it for them? Without making the benefits and incentives clear, relatable and appealing to those who are impacted by metadata management, it’s challenging to gather the much-needed support and commitment to kickstart the initiative in the first place.
Tedious, boring and difficult to implement

How is metadata created? While some metadata is automatically generated by different systems, many details require human users to put in some hard work. For example, you might need to provide the business definitions of 50 different columns presents in a table. Doesn’t sound too bad for a start, right?
But what if there are still 30 more tables to go? Oh yes, once you are done, it’s your job to keep these definitions up to date as well. How would you feel? Unsurprisingly, many people don’t even want to bring it up, fearing that these tedious, labour-intensive and utterly boring tasks would be dropped on their laps.
What’s more? To ensure everyone is on the same page when dealing with metadata, you need to establish standards. This means getting different people to agree on the best way of describing information resources and make sure that they are doing the right thing. Metadata management is difficult to implement. No wonder most people don’t want to have anything to do with it.
Unfortunately, whether you like it or not, the need for proper metadata management will catch up to you in no time. It could be regulatory requirements (e.g. GDPR, CCPA) to track what personally identifiable information your company is capturing and how you are safeguarding such sensitive data. Perhaps once data and analytics have reached a certain scale, your company can no longer afford to keep readily available information resources locked away in silos.
With that being said, below are three general principles to start thinking about metadata management.
- Less is more: Instead of trying to cover all information resources and all types of metadata, prioritise a particular use case that matters most to the business and is achievable within 1-3 months. Metadata should be kept minimal and pertinent to user needs for data discovery and governance requirements.
- Automation over manual labour: Instead of letting your data stewards suffer in silence, consider tools and technologies that automate metadata capture on arrival in the lakes. The options for automated data classification, data lineage tracking and data catalogs are truly endless nowadays.
- User convenience is king: Instead of striving for perfection, aim for simplicity and user convenience when discovering information resources and governing data. The choice of terminologies and vocabularies to describe information resources should reflect the needs of business users.
Parting Thoughts
Admittedly, so much information about someone’s life could be inferred from metadata. An article published in 2015 showed that one year worth of metadata from a reporter’s phone revealed where he lived and worked, how he got to work, when he moved house, where his parents lived and when he went to visit them.
Unsurprisingly, newspaper headlines love using attention-grabbing phrases and dreadful tones when discussing metadata and privacy concerns. But that’s only part of the story.
So which parts are still missing?
Firstly, metadata helps to describe complex items in simple words. In this way, people could easily discover what they have and whether there is anything that might be helpful or relevant for them in an otherwise chaotic and messy world of stuffs.
Secondly, data lakes promise the ability to provide more business users with information resources via a one-stop-shop to generate new revenue streams, optimise costs and improve customer experience. However, without a data catalog, powered by a strong foundation of metadata management, data lakes are rarely functional and ultimately fail to deliver the intended business value.
Finally, metadata management is likely to be a long haul with many roadblocks. Some might feel too hesitant to even begin while other committed souls might give up along the way. It isn’t a system implementation project. It’s a challenging journey of change that deserves lots of active listening, collaboration and empathy.
I sincerely hope you had enjoyed reading this blog post as much as how I enjoyed researching and writing about the topic. Thank you for reading. Have feedback on how I can do better or just wanna chat? Let me know in the comments or find me on LinkedIn. Have a good one, ladies and gents!
