

Asking any developer of an enterprise application, and you’ll know how much they are feeling frustrated with the limitations of relational databases. Too much to the extent that in 2009, Johan Oskarsson decided to host a meetup in San Francisco to discuss with his peers about open-source, distributed, non-relational databases.
Originally chosen to make a good Twitter hashtag for that meetup, NoSQL caught on like wildfire, yet resulted in no generally accepted definition till now. Fast forward to 2021, businesses have an abundance of choice when it comes to data storage solutions, both relational and non-relational ones.
Yet one thing remains the same: The ability to collect, store, analyse and extract insights from data with speed starts with the database you choose. So here are 7 NoSQL basic ideas that you must know to avoid those dreaded pitfalls and “gotcha” moments when choosing the best database for your application. One idea at a time, let’s get started.
Understanding why NoSQL was born
1. From persistent data storage to supporting modern applications
To appreciate why NoSQL was born, I think it’s useful to step back and take a quick look at the evolution of data storage solutions.
Between the 1950s to 1970s, early data management systems such as flat files, hierarchical databases and network databases were created. It was the world when persistent data storage to avoid losing data was simply good enough.
During the 1970s, relational databases came about to solve the problem of having inconsistent data. And so powerful, they became the industry standard to enable separate teams and multiple applications to search, query and operate on a single, logically coherent view of data, resulting in enormous productivity benefits.
But the exponential growth of web applications, e-commerce and social media in the 2000s created new challenges. Tech giants such as Google and Amazon quickly found that catering to a large number of users on the Web was a far cry from supporting thousands of business users on a single database application.
Specifically, we now have a new problem at hand: How to store large datasets consistently and support modern applications which handle tons of user requests in milliseconds continuously without failing? In proper technical terms, it’s the problem of supporting large volumes of read and write operations, low latency response times and high availability.
Although solving this problem with relational databases is possible to a certain extent, it often comes with added complexities and potentially high costs. Thus, born two highly influential examples of NoSQL databases: Bigtable from Google and Dynamo from Amazon. This marked the explosion of NoSQL databases and since then, people have never looked back.
Defining NoSQL characteristics
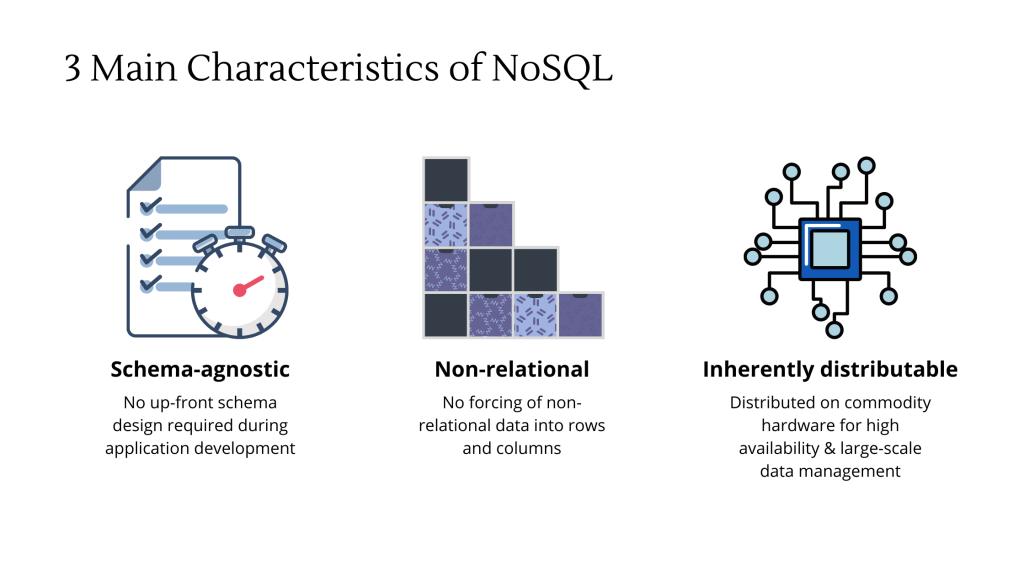
2. Being schema-agnostic
Being schema-agnostic, NoSQL databases don’t require up-front schema design. This implies 2 benefits over relational databases.
Firstly, avoiding spending months on up-front schema design work means shortened development time, which eventually translates to faster time to market for web and mobile applications.
Secondly, being schema-agnostic gives you the flexibility to alter the data structures halfway through the application development (instead of going through the dreaded schema redesign process).
This is important if you are dealing with varying data structures and schema. For example, an e-commerce application would need to store different items with varying product specifications. Fashion products would have size, colour, shape and brand attributes while microwave could include dimension, capacity, wattage and manufacturer’s warranty details.
3. Being non-relational
With a NoSQL database, there is no forcing of non-relational data into rows and columns. As developers can keep the stored data structures much closer to their original form, they can minimise both the amount and the complexity of code to store, manage and search for information. This in turn makes testing, troubleshooting and bug fixing more manageable.
Moreover, as data is stored in a denormalised format, a sales order in a NoSQL database will be saved together with all related products and delivery address. This translates to easy data storage and retrieval as well as faster queries.
If you are thinking denormalising data also has its shortcoming such as redundancy and higher data storage costs. You’re absolutely right! At the end of the day, it’s a matter of judging how much you are willing to pay for faster application development and data query.
4. Being inherently distributable on commodity hardware
It’s a given that any modern application has to be distributed across multiple commodity servers. It’s not only to cater to the large volumes of data but also the consumer expectations for seamless always-on websites and applications. They have to respond in milliseconds and always be available to many concurrent users whenever needed.
Oracle RAC or SQL Server AlwaysOn are examples of distributed relational databases. Unfortunately, relational databases have to rely on manual sharding, which usually leads to greater complexity and cost to operations.
On the contrary, many NoSQL databases such as HBase, Riak and Cassandra are inherently distributed, with built-in options to control how data is replicated and distributed across cheap commodity servers. Even if one of the servers crashes or burns, your data will still be accessible for your application to continue running and serving users’ needs. This makes NoSQL databases a better fit for large-scale data storage to support websites and customer-facing applications.
Note: Not all NoSQL databases are designed to be distributed or have to be distributed. However, when availability and scalability are top concerns, it makes sense to opt for distributed offerings.
Selecting NoSQL databases
5. There exist more than one types of NoSQL databases
NoSQL databases come in four most widely used types: key-value, document, column family, and graph databases. Each serves very different purposes.
- Key-value databases save data as a group of key-value pairs. The key acts as a unique identifier to look up the associated value. Some examples include Memcached, Voldemort, Redis and Riak.
- Document databases store and query data as JSON-like documents with nested structures. Two major open-source options are MongoDB and CouchDB.
- Column-oriented databases are designed in a way that data from a given column is stored together. Some of the more popular offerings are HBase, Cassandra, Hypertable.
- Graph databases’ strength lies in their ability to model networks (i.e. things connected to other things). Often found in social networking applications, graph databases can quickly transverse nodes and relationships to extract relevant data. You might have already heard about its most well-known example: Neo4J.
NoSQL databases come with an abundance of choices, yet all choices aren’t created equally. The wide range of NoSQL offerings indicates one may excel in managing documents while another offers an unparalleled advantage to manage social networks. Here are some real-life use cases for each NoSQL database type.

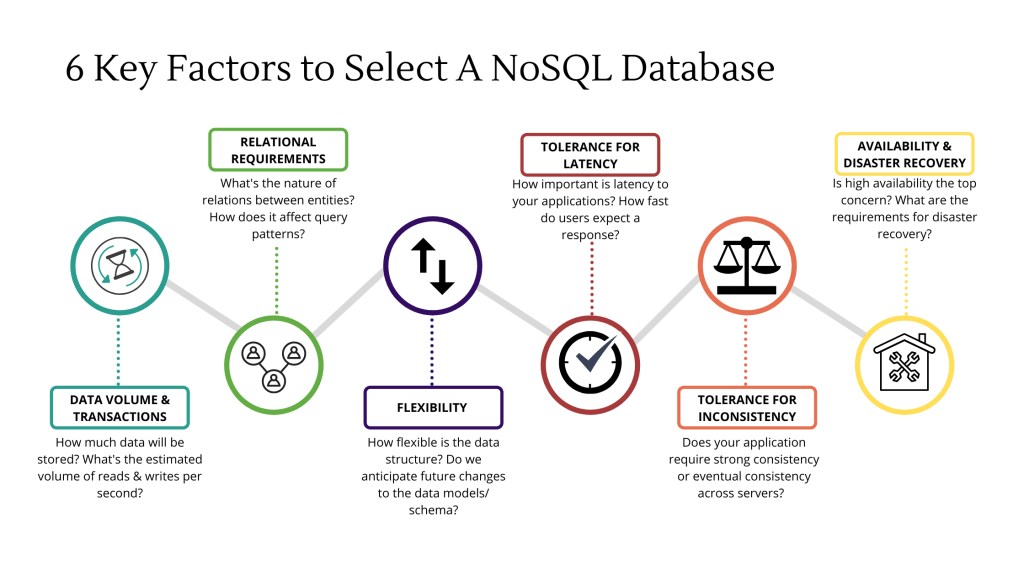
6. The best fit for your business problem
When choosing which NoSQL databases to adopt, the question you must ask yourself is not “Can this database store my data?” but rather, “Is it the best fit for my business problem and application requirements?”
But it’s clear to me and many others that determining the “best fit” can be tough, given there are so many considerations. Each consideration carries a different weightage to the final decision for disparate use cases.
To give you a starting point, below are 6 key factors that must be taken into account when deciding the best fit for a data storage solution.
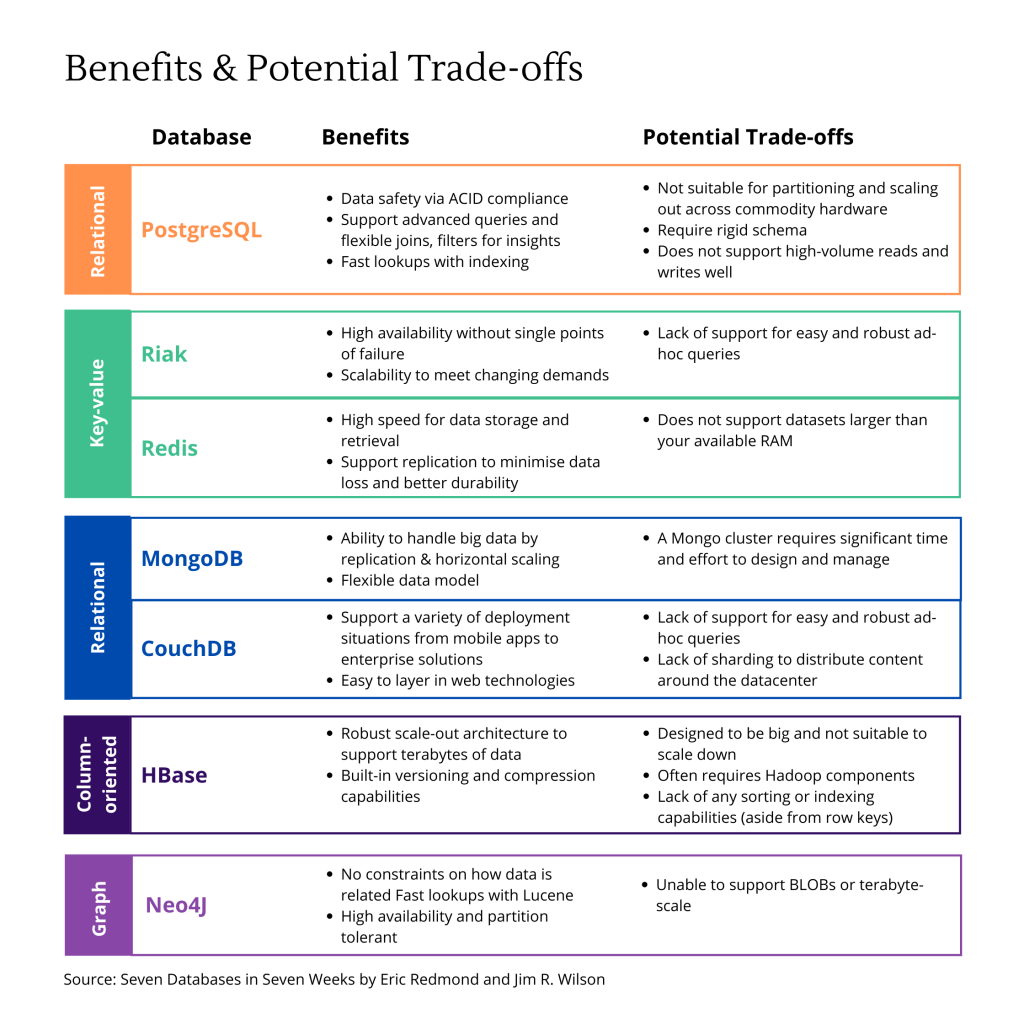
7. Each choice comes with certain trade-offs
As the database landscape is changing more rapidly than we dare predict, choosing the best option is really complex.
For example, although a graph database like Neo4J would be perfect for social media like Facebook, the sheer volume of data stored would easily overwhelm any existing graph databases. As such, it makes sense to gravitate towards more large-scale options such as HBase or Riak, which initially have got nothing to do with social networks.
The point here is that each NoSQL database should be evaluated as an individual technology instead of being stereotyped based on its classification. Potential trade-offs will have to be carefully considered as they could be the deal-breakers.
To illustrate this point, below is a simplified comparison between selected databases from the book Seven Databases in Seven Weeks.
Note: In the table, I have also included the relational PostgreSQL to highlight the trade-offs for choosing a relational database over other non-relational peers. Also, new features might be released to address some potential trade-offs as we speak, so it’s best to check the latest updates.
Wrapping Up
NoSQL means “Not Only SQL”, and it doesn’t simply represent a new kid on the block to help organisations store and manage data better. The “not-only” notion describes a movement where relational databases (using SQL) is still here to stay but no longer the only option for data storage. It’s a future where we also have other alternatives to address new requirements that stretch beyond what traditional relational databases can offer.
Since there is no going back to the single option for data storage, organisations now have the freedom to adopt a mix of different databases to solve different problems (a.k.a. polyglot persistence). Each will play to their strengths yet they will all coexist (hopefully in harmony) in the same ecosystem.
And this brings us to the most important takeaway from this post. Every choice comes with a consequence. Hence, it’s important for us to commit the time and efforts to understand the implications, the potential trade-offs and the ultimate responsibility that comes with our decision on data storage technologies. After all, you can’t escape the consequences of your choices, whether you like them or not.
If you’re reading this, thank you for your time and I really hope you got some value from this post. Feel free to connect with me on LinkedIn and Twitter. Have a good one!
